
Storm的配置及实验报告

目录
一、 实验内容
Storm的配置
Ø JDK的安装与配置
Ø ZooKeeper的安装与配置
Ø Storm的安装与配置
二、 实现方法
JDK的安装与配置,这个在很早以前就已经配置过了,由于最新版本的java直接一键安装即可,故这个部分非常简单。

设置环境变量:
Ø 新增环境变量STORM_HOME并设置为D:\apache-storm-1.2.2
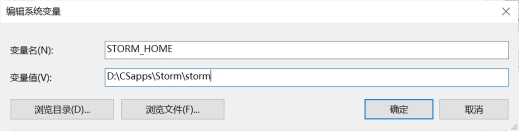
Ø 在Path里新增%STORM_HOME%\bin
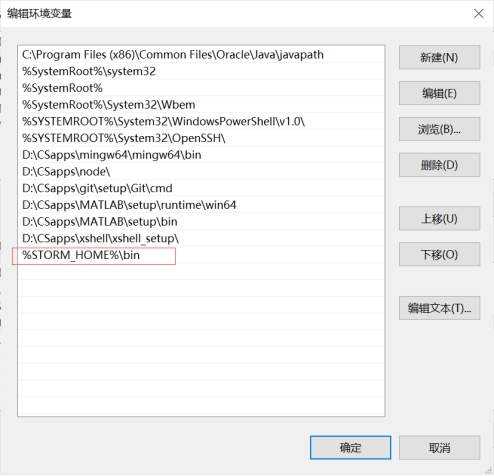
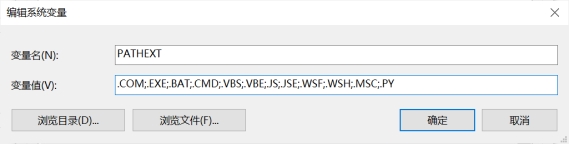
Ø 在PATHEXT路径中加入.PY
Ø
Ø 在storm下找到E\conf storm.yaml 将其内容复制为:
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
########### These MUST be filled in for a storm configuration
# storm.zookeeper.servers:
# - "server1"
# - "server2"
storm.zookeeper.servers:
- "127.0.0.1"
#
# nimbus.seeds: ["host1", "host2", "host3"]
nimbus.seeds: ["127.0.0.1"]
storm.local.dir: "D:\\storm-local\\data3"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
#
#
# ##### These may optionally be filled in:
#
## List of custom serializations
# topology.kryo.register:
# - org.mycompany.MyType
# - org.mycompany.MyType2: org.mycompany.MyType2Serializer
#
## List of custom kryo decorators
# topology.kryo.decorators:
# - org.mycompany.MyDecorator
#
## Locations of the drpc servers
# drpc.servers:
# - "server1"
# - "server2"
## Metrics Consumers
## max.retain.metric.tuples
## - task queue will be unbounded when max.retain.metric.tuples is equal or less than 0.
## whitelist / blacklist
## - when none of configuration for metric filter are specified, it'll be treated as 'pass all'.
## - you need to specify either whitelist or blacklist, or none of them. You can't specify both of them.
## - you can specify multiple whitelist / blacklist with regular expression
## expandMapType: expand metric with map type as value to multiple metrics
## - set to true when you would like to apply filter to expanded metrics
## - default value is false which is backward compatible value
## metricNameSeparator: separator between origin metric name and key of entry from map
## - only effective when expandMapType is set to true
# topology.metrics.consumer.register:
# - class: "org.apache.storm.metric.LoggingMetricsConsumer"
# max.retain.metric.tuples: 100
# parallelism.hint: 1
# - class: "org.mycompany.MyMetricsConsumer"
# max.retain.metric.tuples: 100
# whitelist:
# - "execute.*"
# - "^__complete-latency$"
# parallelism.hint: 1
# argument:
# - endpoint: "metrics-collector.mycompany.org"
# expandMapType: true
# metricNameSeparator: "."
## Cluster Metrics Consumers
# storm.cluster.metrics.consumer.register:
# - class: "org.apache.storm.metric.LoggingClusterMetricsConsumer"
# - class: "org.mycompany.MyMetricsConsumer"
# argument:
# - endpoint: "metrics-collector.mycompany.org"
#
# storm.cluster.metrics.consumer.publish.interval.secs: 60
# Event Logger
# topology.event.logger.register:
# - class: "org.apache.storm.metric.FileBasedEventLogger"
# - class: "org.mycompany.MyEventLogger"
# arguments:
# endpoint: "event-logger.mycompany.org"
# Metrics v2 configuration (optional)
#storm.metrics.reporters:
# # Graphite Reporter
# - class: "org.apache.storm.metrics2.reporters.GraphiteStormReporter"
# daemons:
# - "supervisor"
# - "nimbus"
# - "worker"
# report.period: 60
# report.period.units: "SECONDS"
# graphite.host: "localhost"
# graphite.port: 2003
#
# # Console Reporter
# - class: "org.apache.storm.metrics2.reporters.ConsoleStormReporter"
# daemons:
# - "worker"
# report.period: 10
# report.period.units: "SECONDS"
# filter:
# class: "org.apache.storm.metrics2.filters.RegexFilter"
# expression: ".*my_component.*emitted.*"
最后就是运行部分:首先,先确保zookeeper是打开的状态(运行bin目录下的zkSever.cmd),之后进入到Strom的bin目录下,分别运行storm.py nimbus、storm.py supervisor和storm.py ui指令。
Ø zookeeper打开
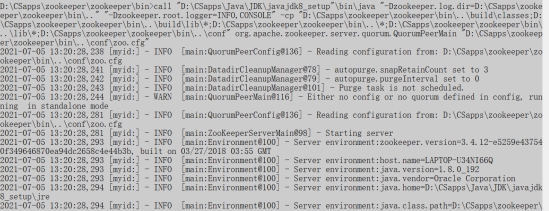
Ø 运行storm.py nimbus

Ø Storm.py supervisor

Ø Storm.py ui

可以看到,成功运行,配置完成。
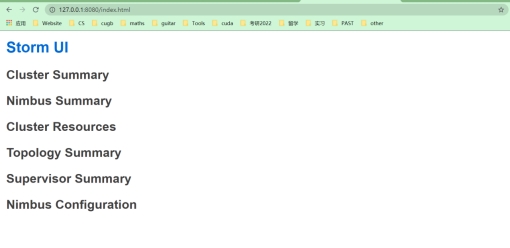
三、 结果分析
在打开zookeeper、nimbus、supervisor、ui可以成功得检验storm的安装。在windows系统下的安装较为简单,但是对于初学的我们仍然带来了很大的挑战。
四、 结论与展望
Storm是一个分布式的、容错的实时计算系统。Storm为分布式实时计算提供了一组通用原语,可被用于“流处理”之中,实时处理消息并更新数据。Storm可以方便地在一个计算机集群中编写与扩展复杂的实时计算,Storm用于实时处理。综上所述,Storm具有广阔的应用前景和丰厚的应用价值,学习好Storm对同学们今后的学习和工作都有十分巨大的帮助。