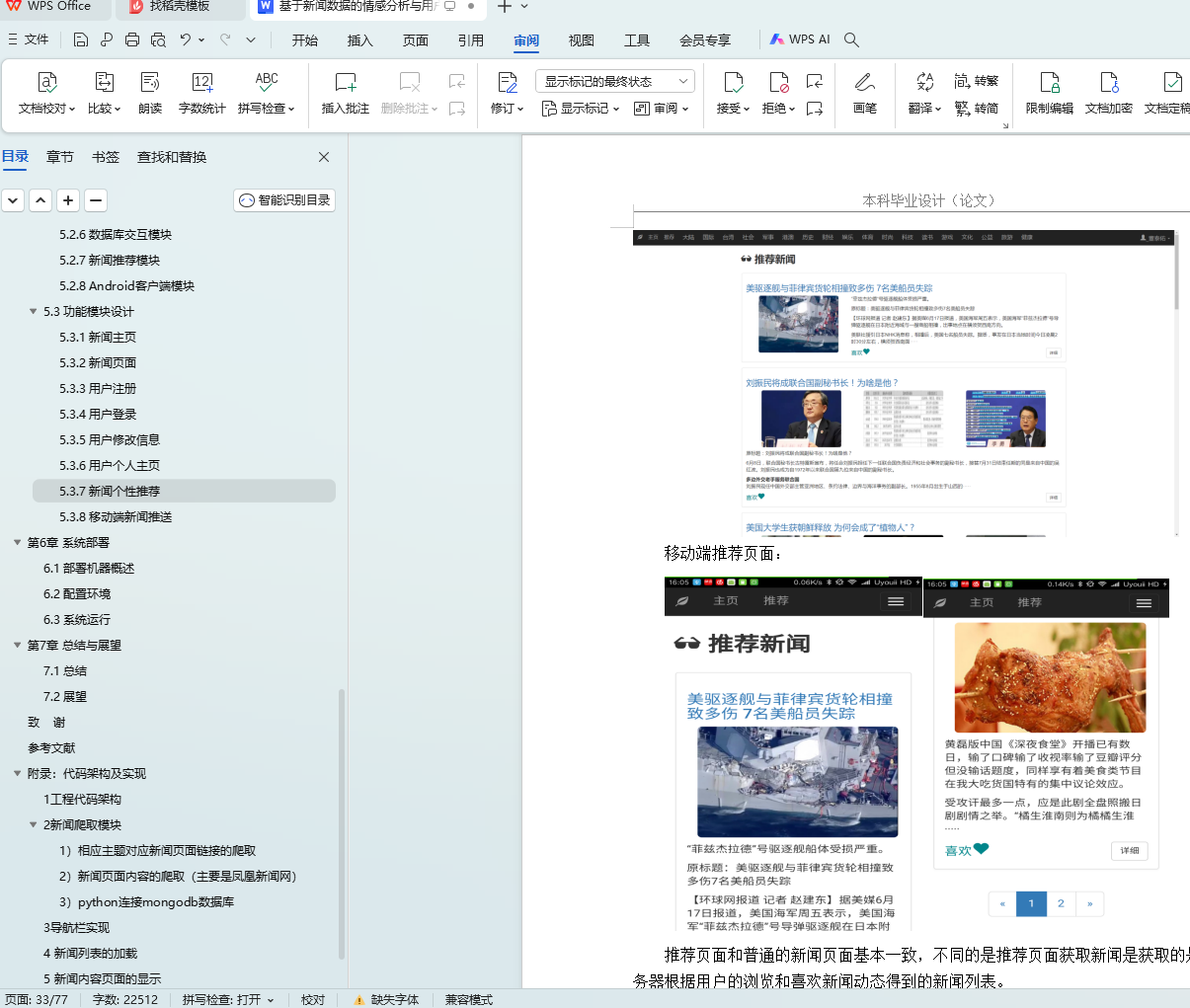
基于新闻数据的情感分析与用户推荐系统的设计与实现 毕业论文+任务书+开题报告+文献综述+答辩稿+答辩PPT+论文检测查重报告+项目源码

摘 要
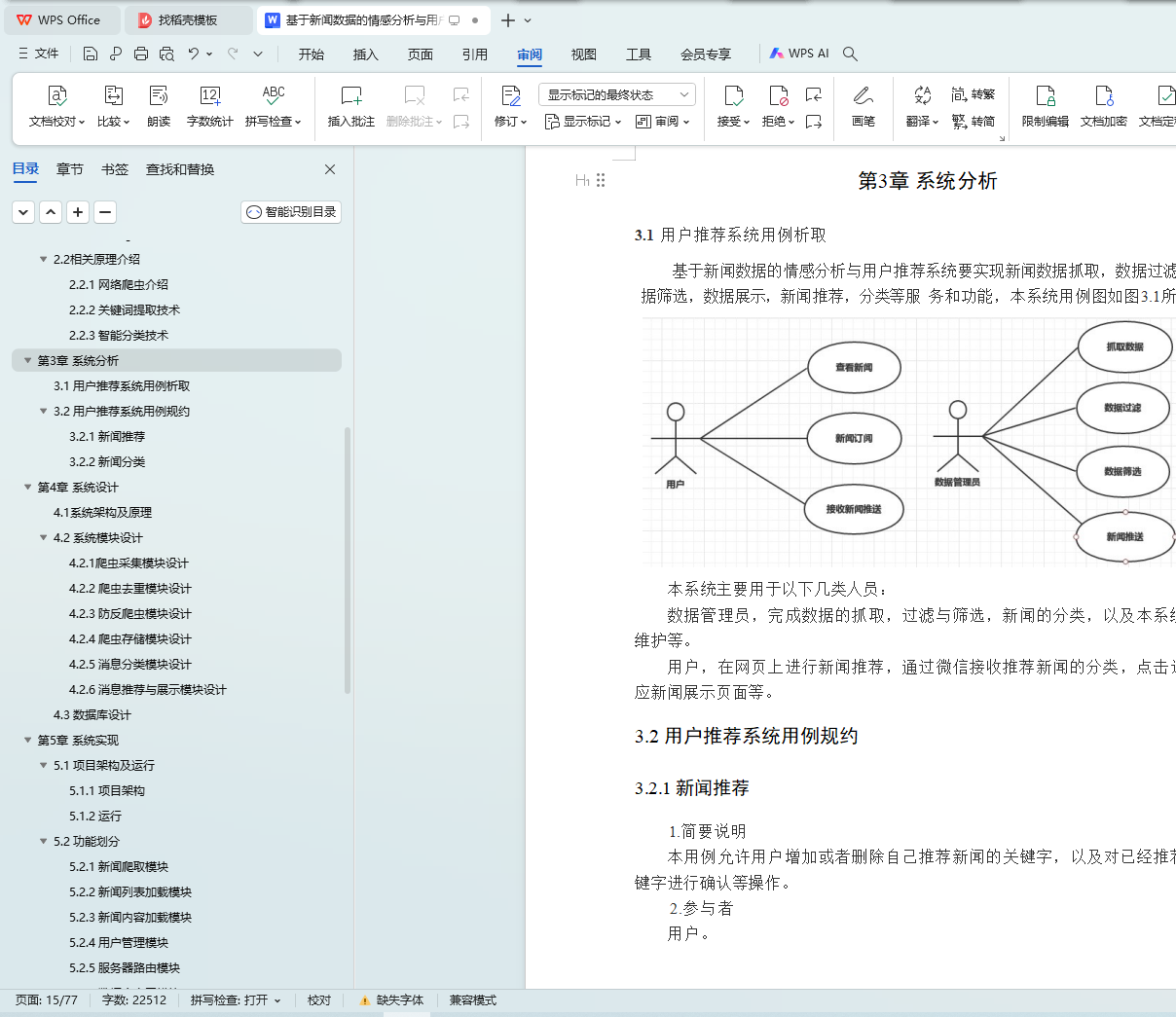
本选题来源于对现代信息处理和人工智能技术的深入探索,以及对新闻传媒行业发展趋势的敏锐观察。在当今信息爆炸的时代,新闻数据的规模呈现出前所未有的增长,如何有效地处理和分析这些数据,为用户提供精准、有价值的新闻信息,成为了一个亟待解决的问题。同时,随着人工智能技术的发展,情感分析和用户推荐系统成为了解决这一问题的有力工具。因此,本选题旨在结合Python爬虫技术、情感分析技术和用户推荐系统,设计并实现一个能够为用户提供个性化新闻服务的系统,旨在提升新闻阅读的效率和体验。
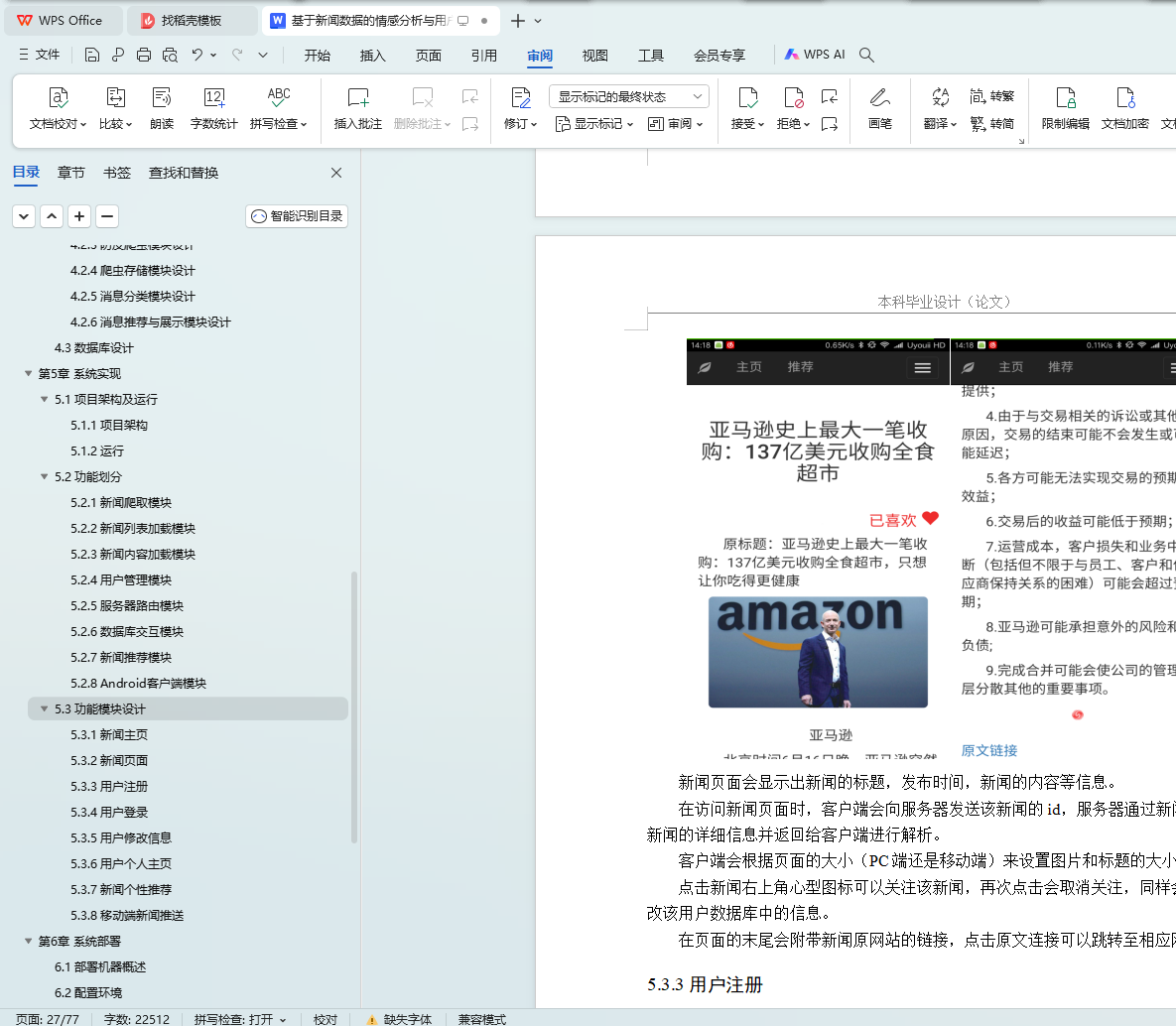
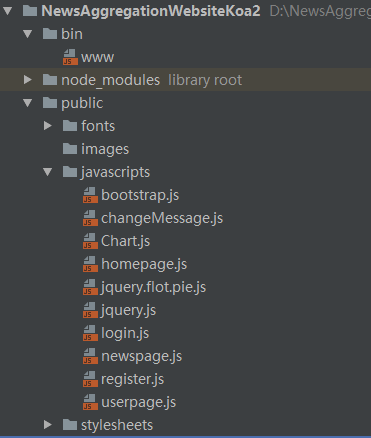
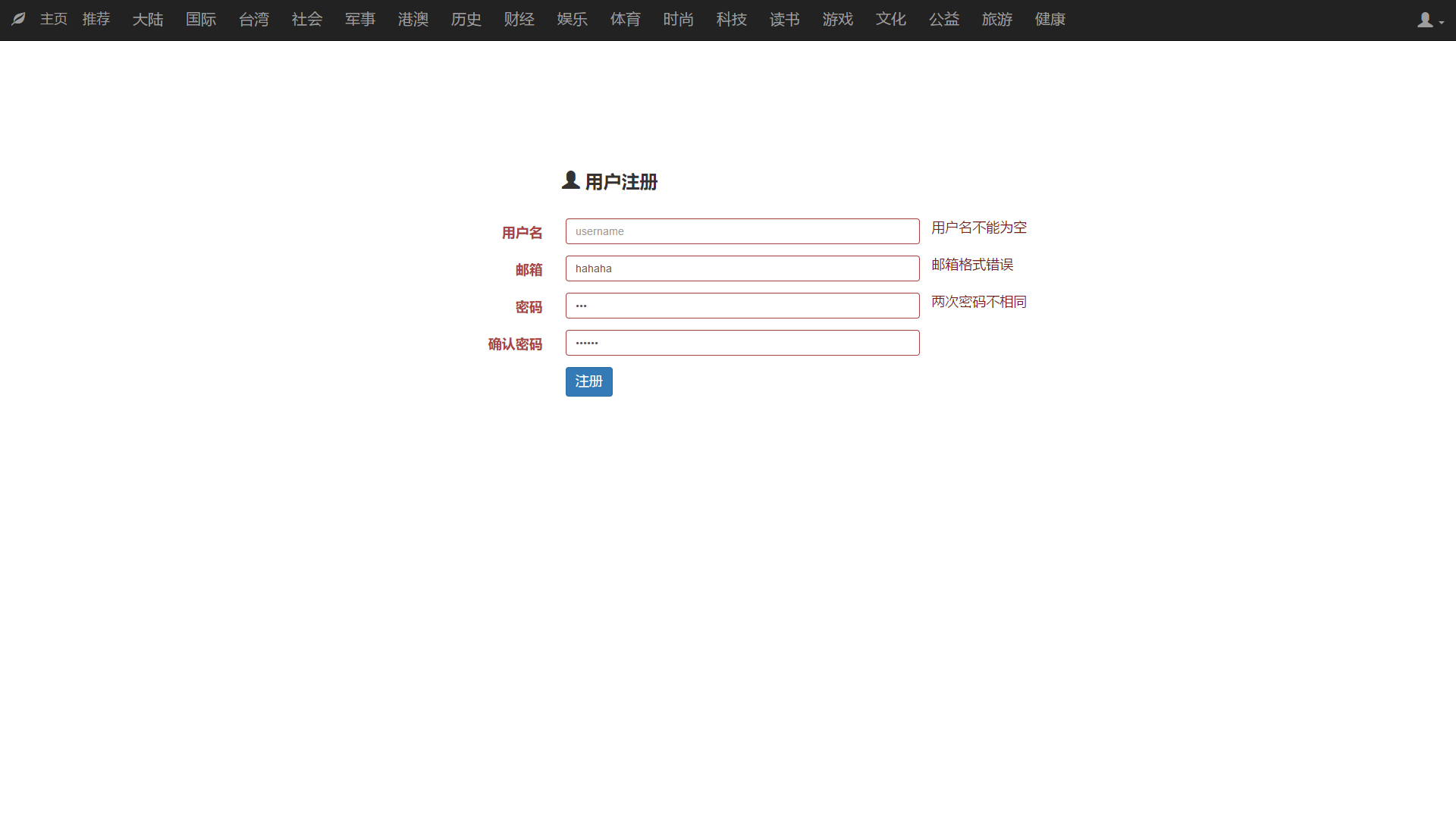
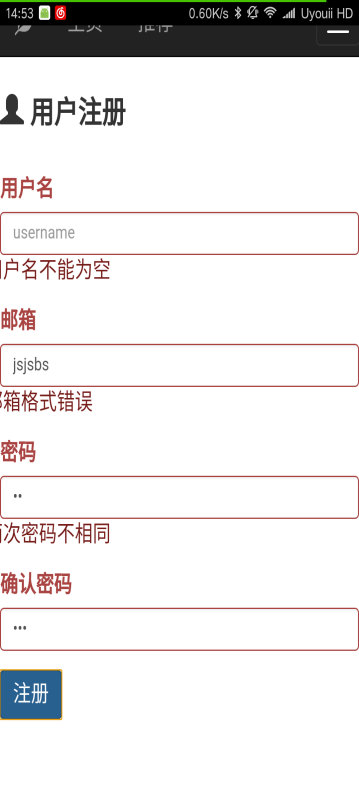
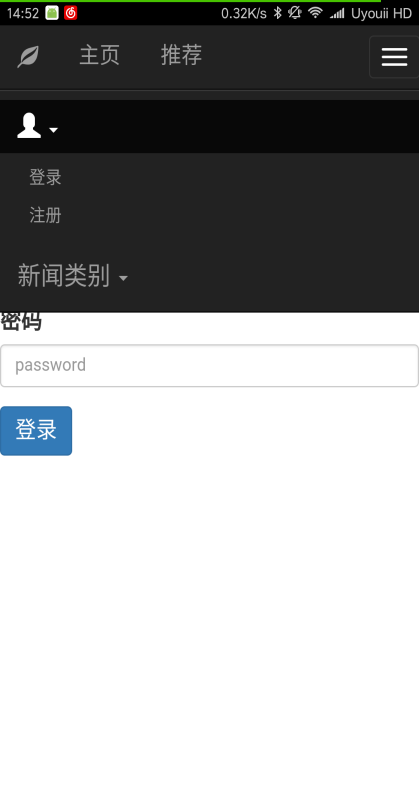
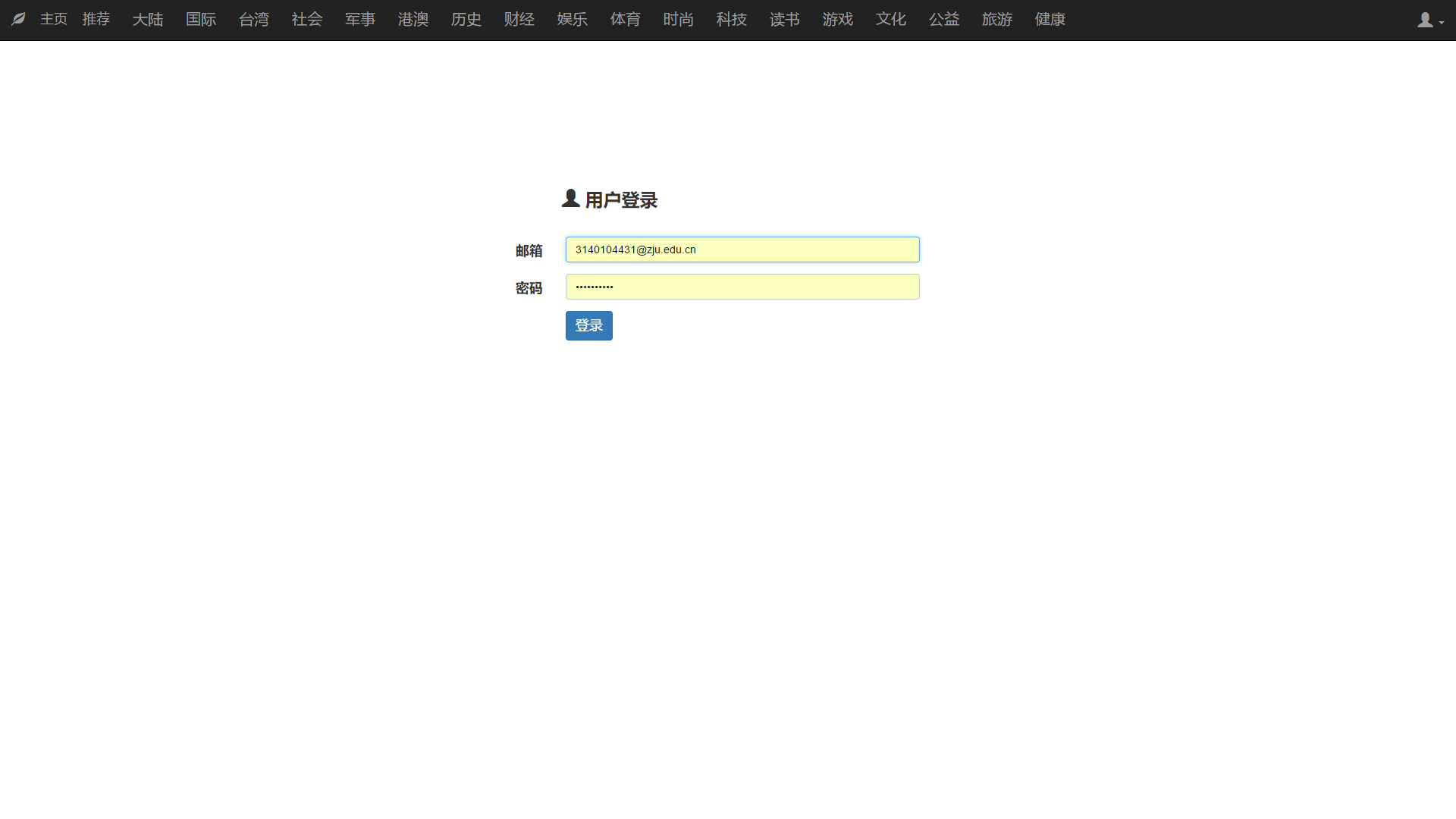
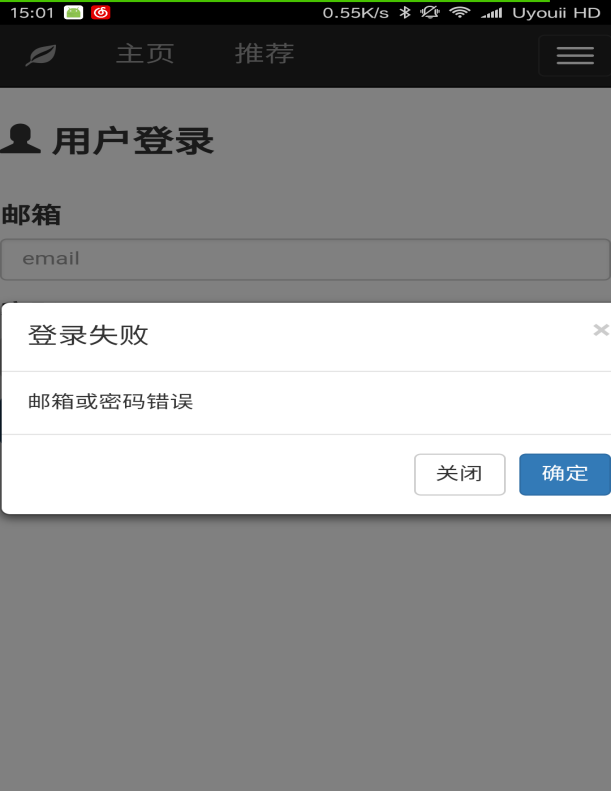
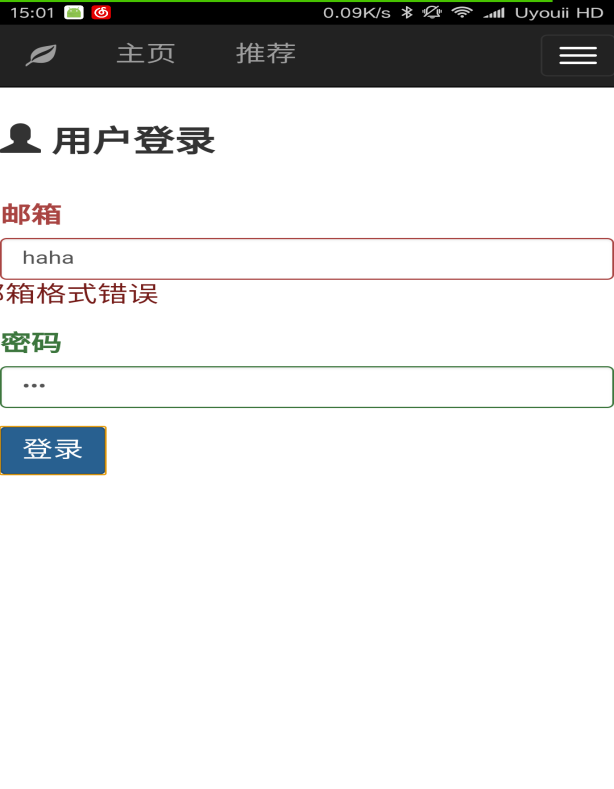
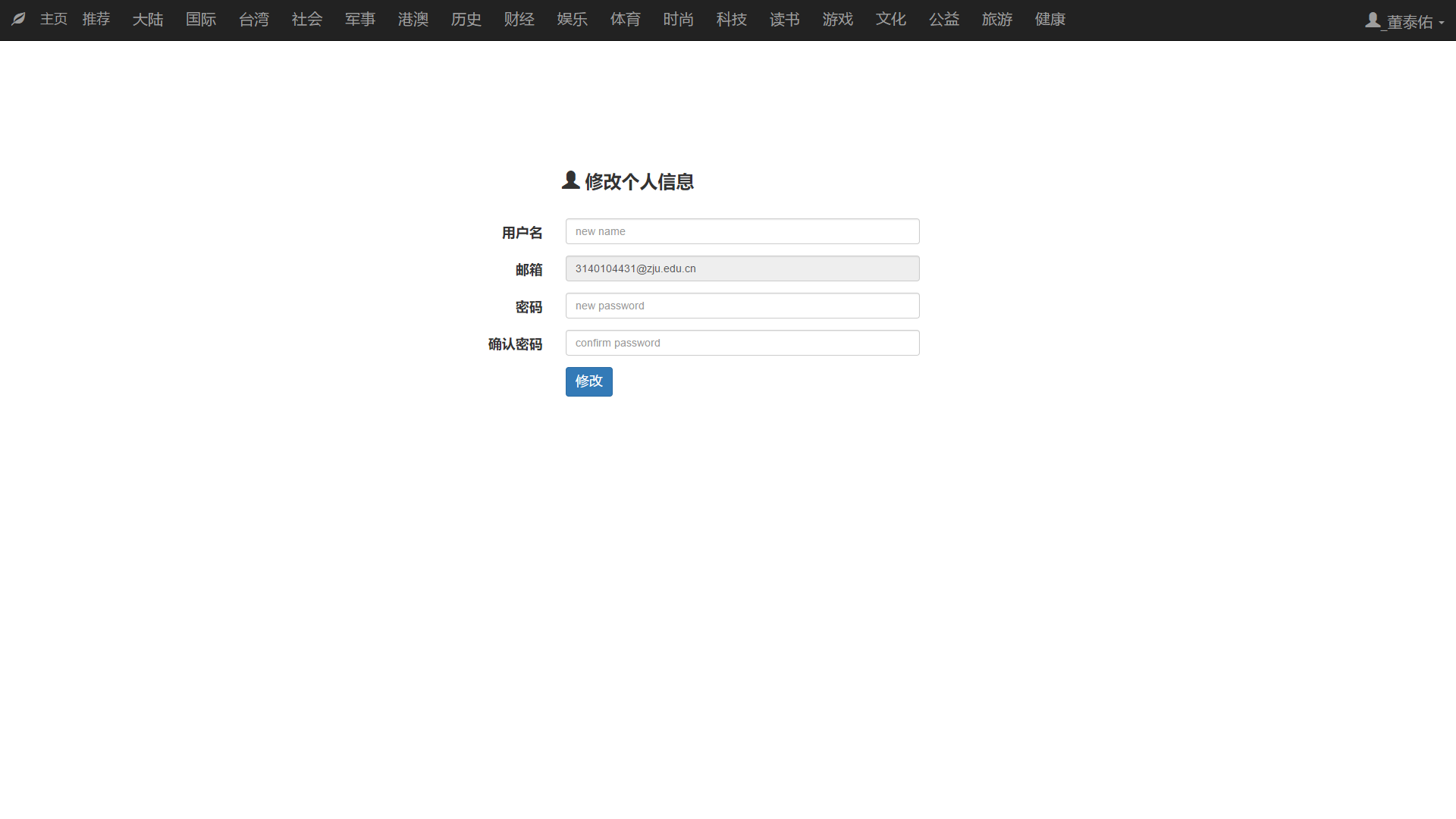
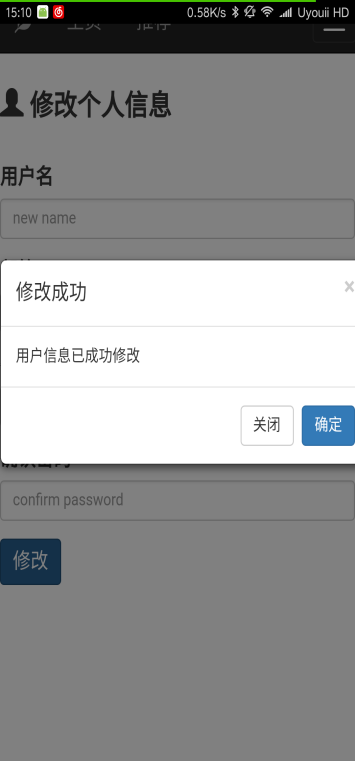
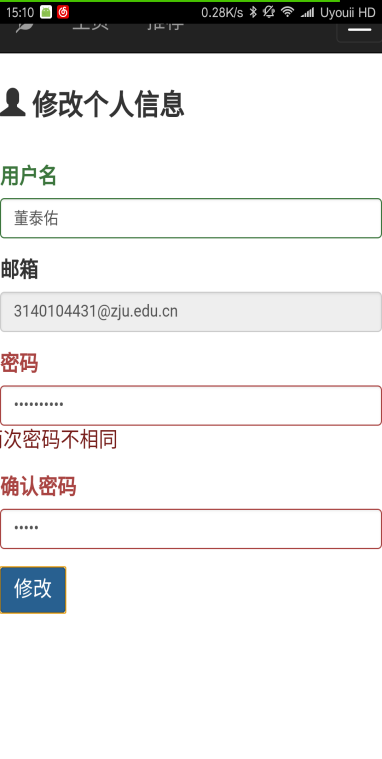
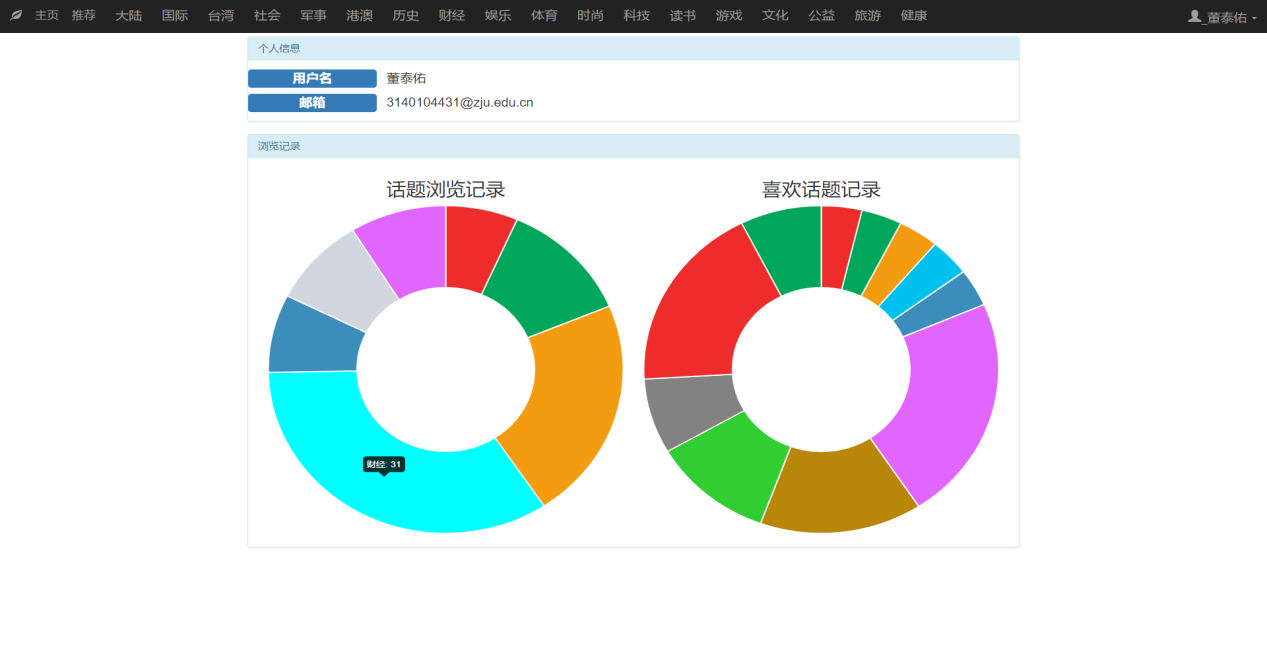
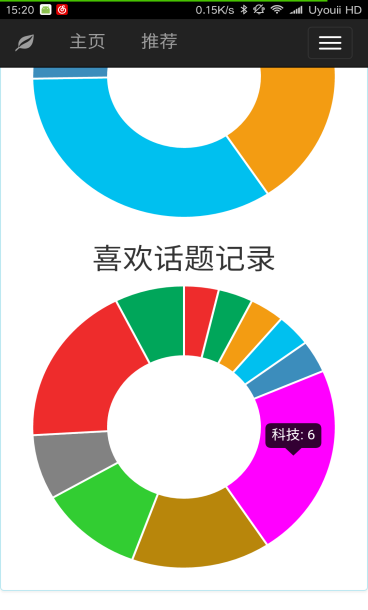
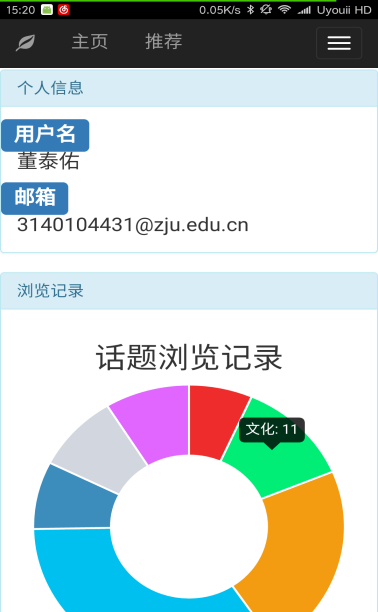
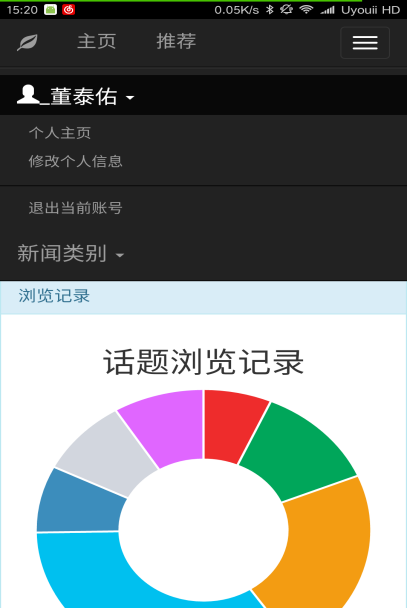
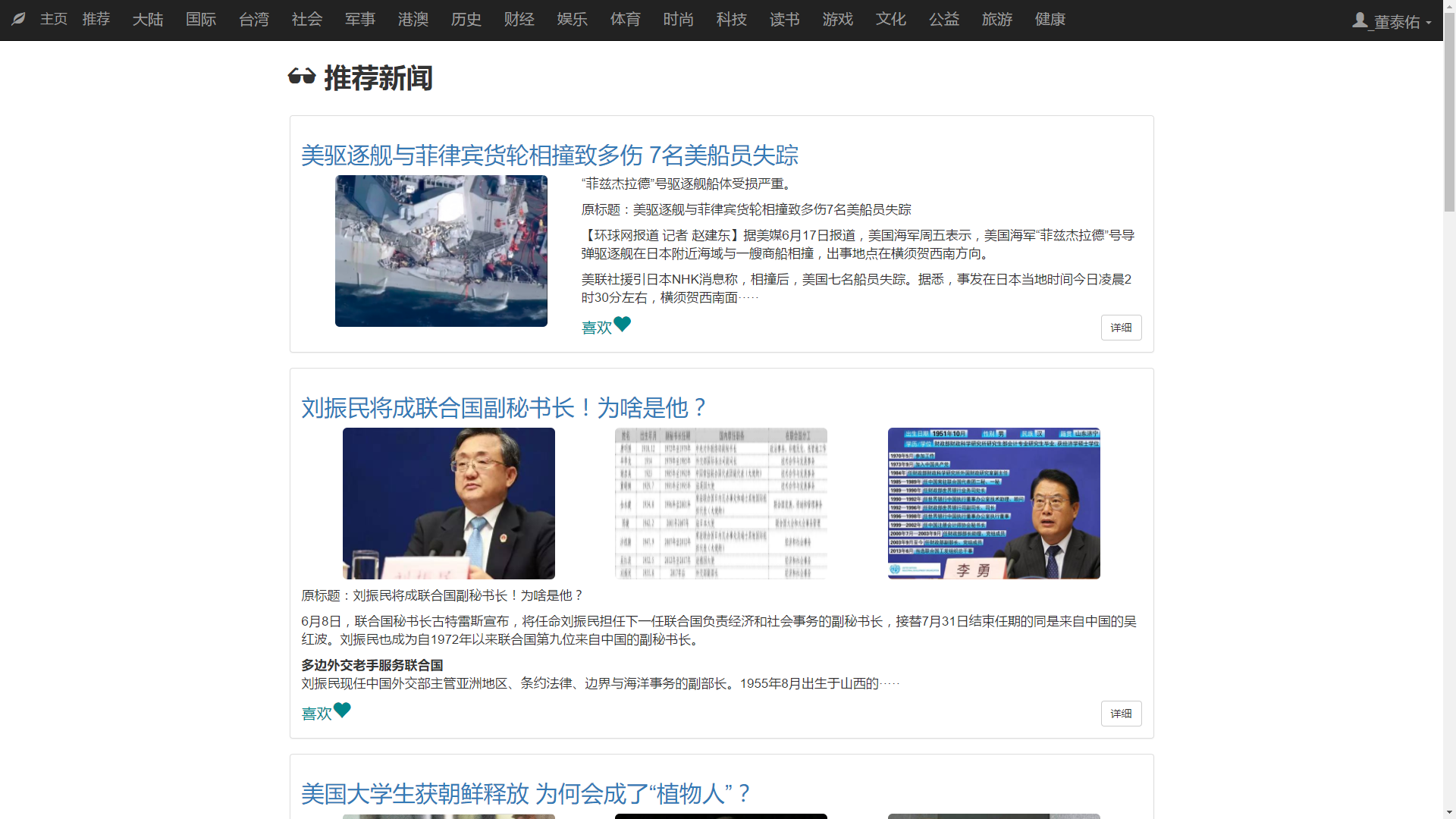
本文研究了基于新闻数据的情感分析与用户推荐系统的设计与实现。利用Python的Scrapy框架,设计了一个能够定时定向分析和采集网络新闻数据的爬虫网络。该系统不仅实现了新闻数据的分类、去重和存储,还通过用户分享、评论等功能,构建了一个全新的新闻网站。为了提升用户体验,本文进一步实现了新闻数据的可视化,旨在帮助用户在海量新闻数据中快速获取有价值的信息。此外,针对网站的反爬虫策略,本文提出了应对策略,以确保爬虫的稳定运行。技术实现上,前端采用bootstrap框架,后端采用node.js的koa2框架,数据库使用mongodb,确保了系统的可扩展性和灵活性。用户可以通过浏览器或Android APP访问该网站,享受个性化的新闻推荐和便捷的新闻浏览体验。
关键词:新闻数据;情感分析;用户推荐系统;Python爬虫;新闻聚合
Abstract
This topic comes from the in-depth exploration of modern information processing and artificial intelligence technology, as well as the keen observation of the development trend of the news media industry. In today's era of information explosion, the scale of news data has shown an unprecedented growth. How to effectively process and analyze these data and provide users with accurate and valuable news information has become an urgent problem to be solved. At the same time, with the development of artificial intelligence technology, sentiment analysis and user recommendation systems have become a powerful tools to solve this problem. Therefore, this topic aims to design and implement a system that can provide users with personalized news services by combining Python crawler technology, emotion analysis technology and user recommendation system, aiming to improve the efficiency and experience of news reading.
This paper studies the design and implementation of emotion analysis and user recommendation system based on news data. Using the Scrapy framework of Python, a crawler network capable of timing and directional analysis and collecting network news data is designed. The system not only realizes the classification, weight and storage of news data, but also builds a new news website through user sharing, comment and other functions. In order to improve the user experience, this paper further realizes the visualization of news data, aiming to help users to quickly obtain valuable information from the massive news data. Moreover, for the website anti-crawler strategies, this paper proposes coping strategies to ensure the stable operation of the crawler. In the technical implementation, the front end adopts bootstrap framework, the back end adopts node.js koa 2 framework, and the database uses mongodb, which ensures the scalability and flexibility of the system. Users can access the site through a browser or Android APP to enjoy personalized news recommendations and convenient news browsing experience.
Key words: news data; emotion analysis; user recommendation system; Python crawler; news aggregation
目 录