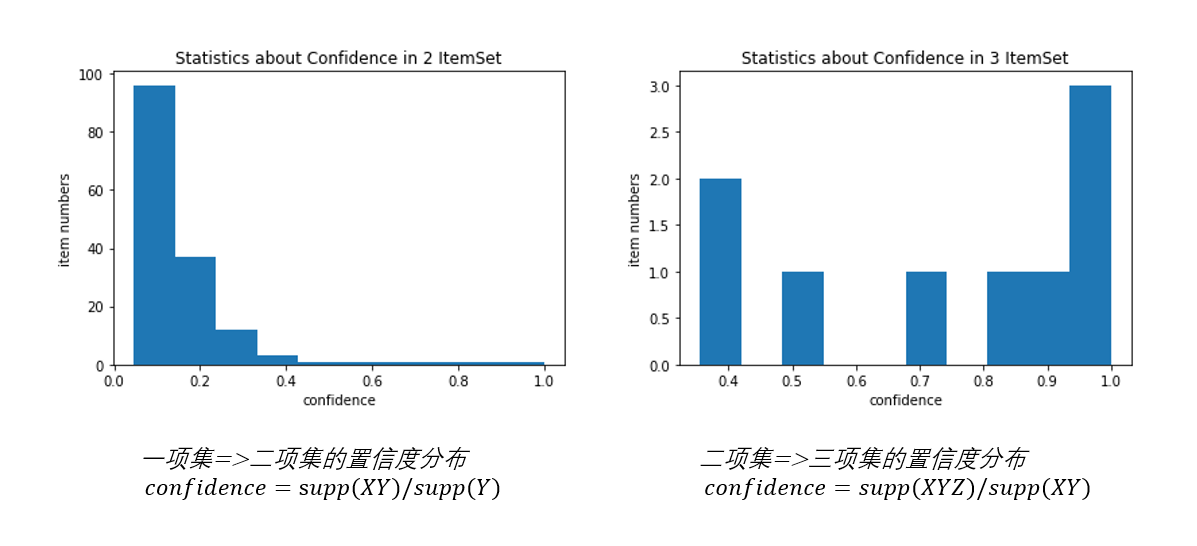
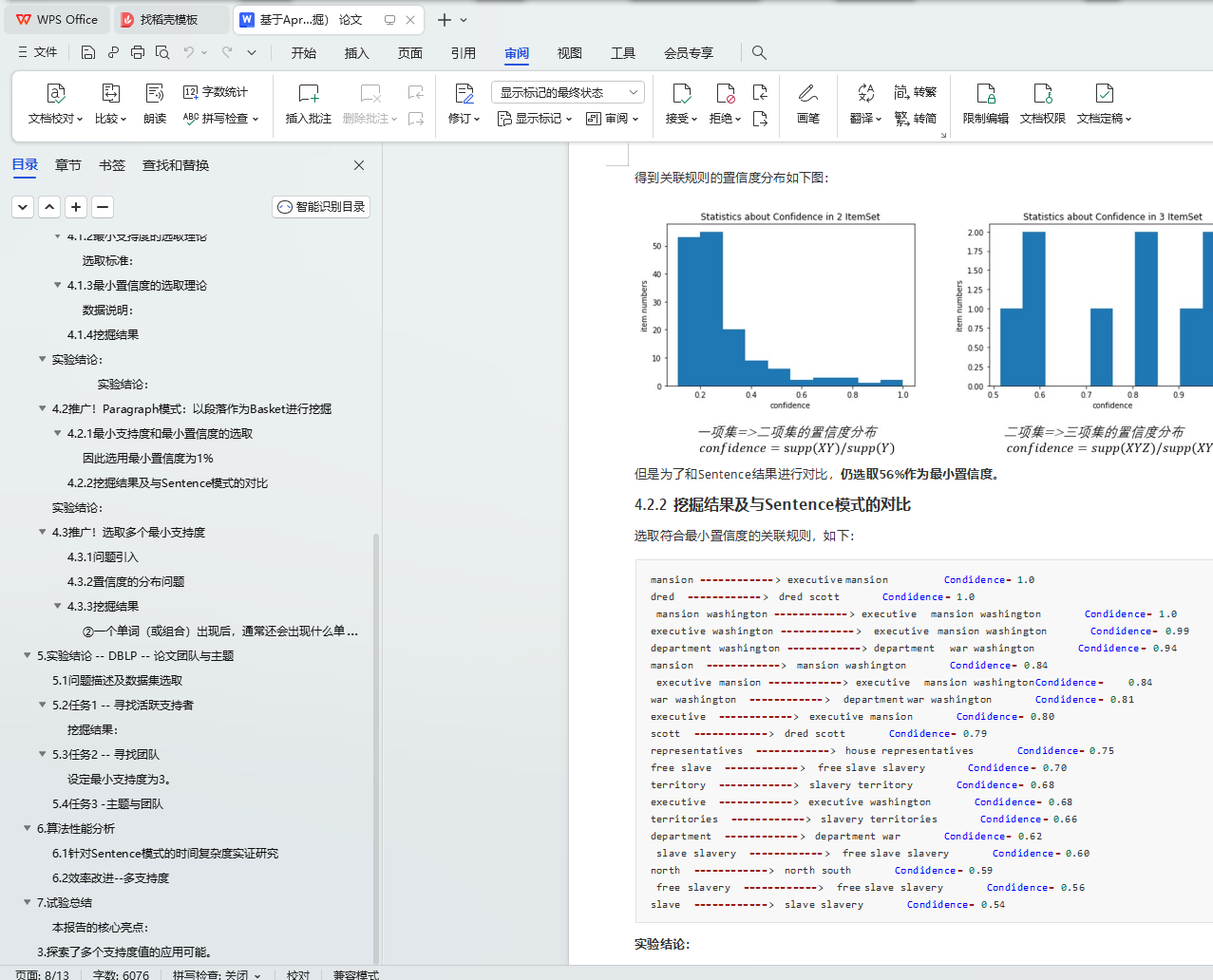
基于Apriori算法的多粒度的频繁模式数据挖掘(选取GutenBerg数据集和DBLP数据集进行挖掘) 论文+源码及数据

数据仓库大作业--频繁模式挖掘


目录
4. 实验结论 -- GutenBerg -- 林肯演讲集:挖掘常用词共同出现
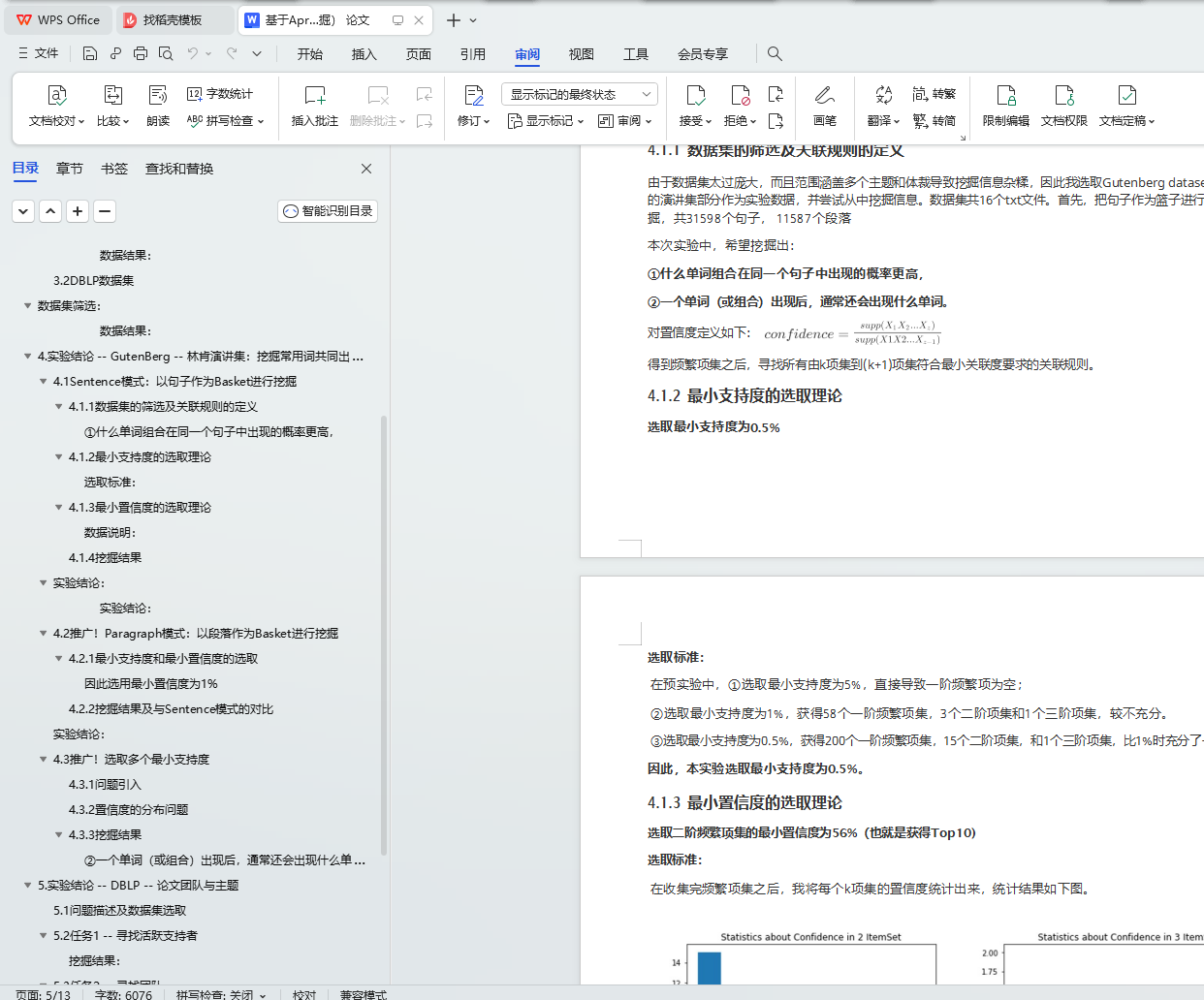
4.1 Sentence模式:以句子作为Basket进行挖掘
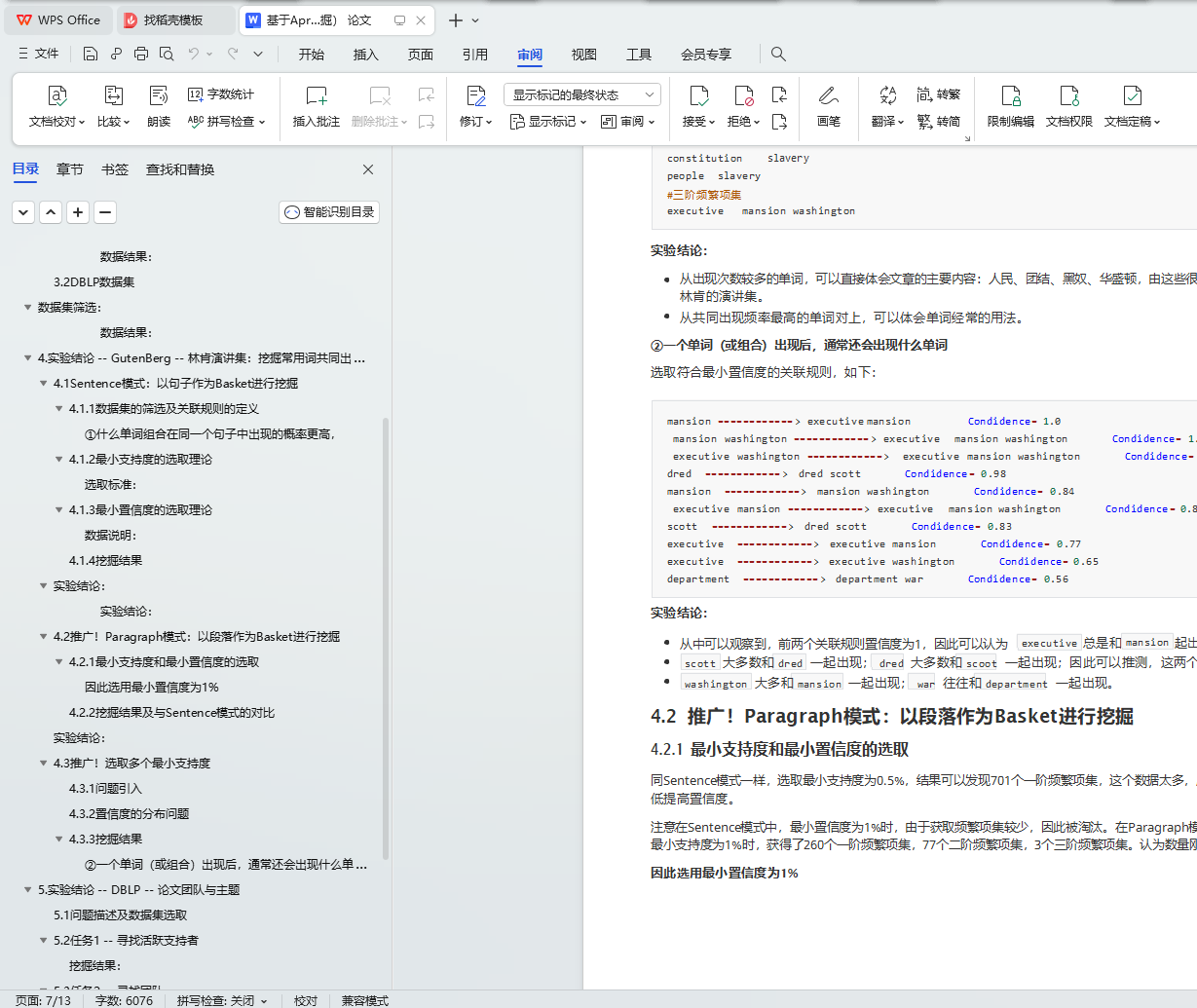
4.2 推广!Paragraph模式:以段落作为Basket进行挖掘
1. 实验综述

关联分析常常用于从大规模数据库中寻找元素的隐含关系,是数据仓库中数据挖掘的最常用的方法。本实验旨在实 现基本的数据挖掘算法(Apriori算法),选取部分数据集数据进行挖掘。在探寻数据隐含关系的同时,试图评估数 据挖掘算法的性能和特性。
本报告主要包括以下部分:
1. 实验原理(包括算法详细描述、算法特点等)
2. 实验环境搭建(数据集的选取、挖掘的问题、编程环境简述)
3. 实验发现
4. 算法性能分析
本报告的核心亮点:
1. 实现了Apriori算法,并对算法效率进行了实证性研究,应用了潜在解决方案。
2. 进行了多粒度的数据挖掘(选取了句子和段落作为两种篮子,并比较二者区别)。
3. 探索了多个支持度值的应用可能。
4. 进行了多数据集的应用(GutenBerg &&DBLP),对每个数据集进行了多个问题多个角度的研究探讨。