基于python的电影票房数据爬取与可视化系统的设计与实现 毕业论文+任务书+开题报告+答辩PPT+答辩稿+项目源码+演示视频+查重报告

摘 要
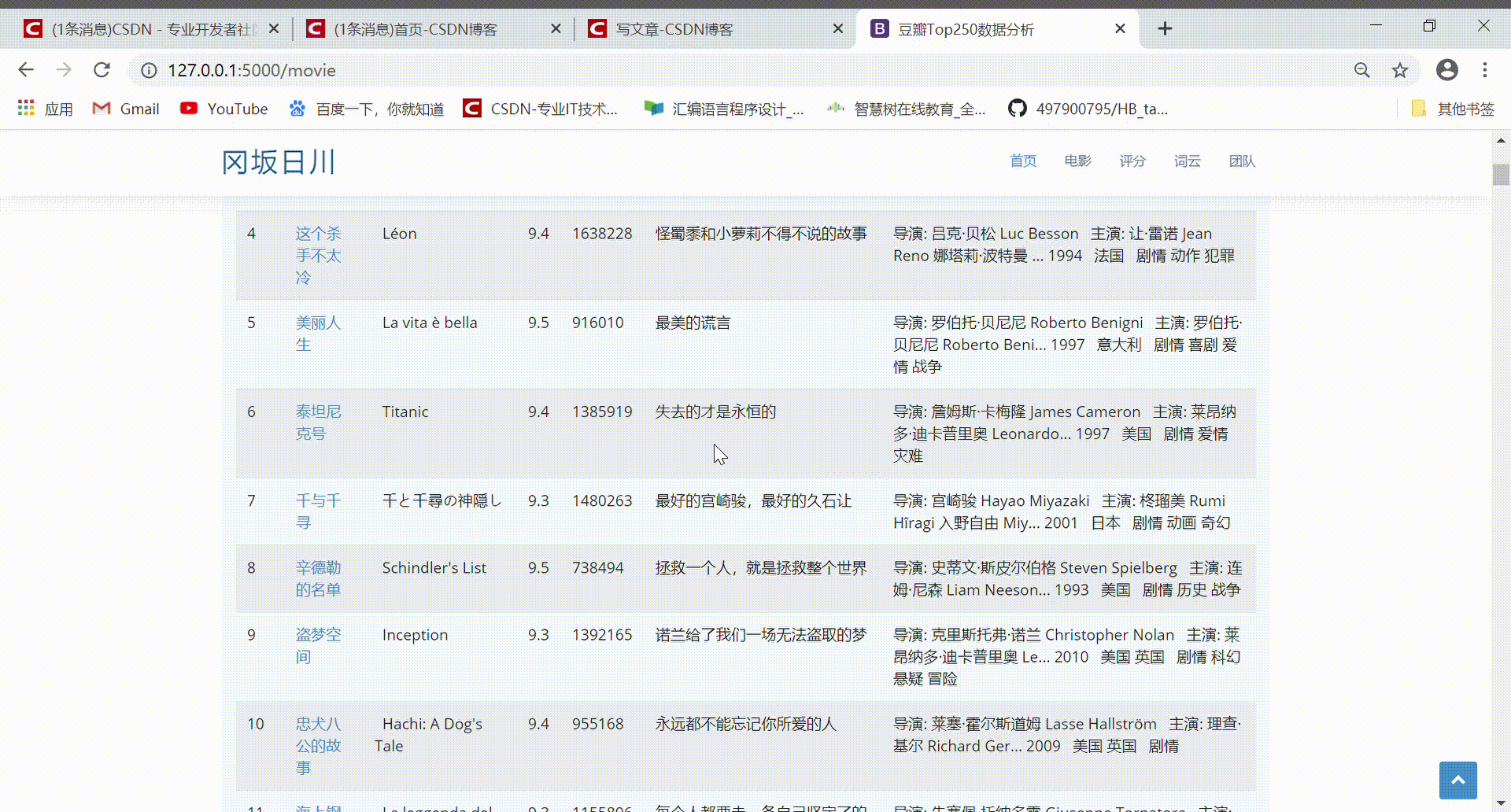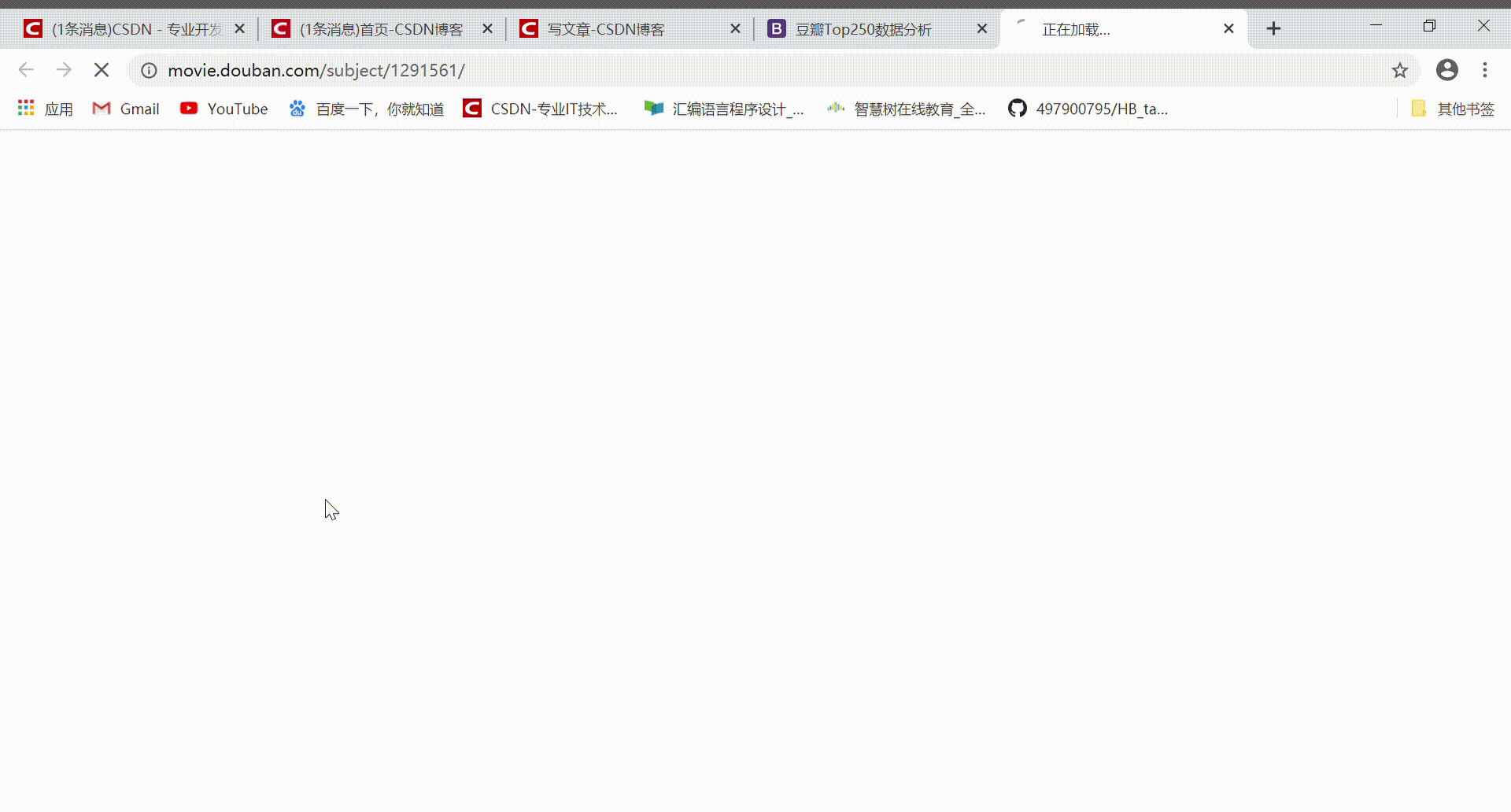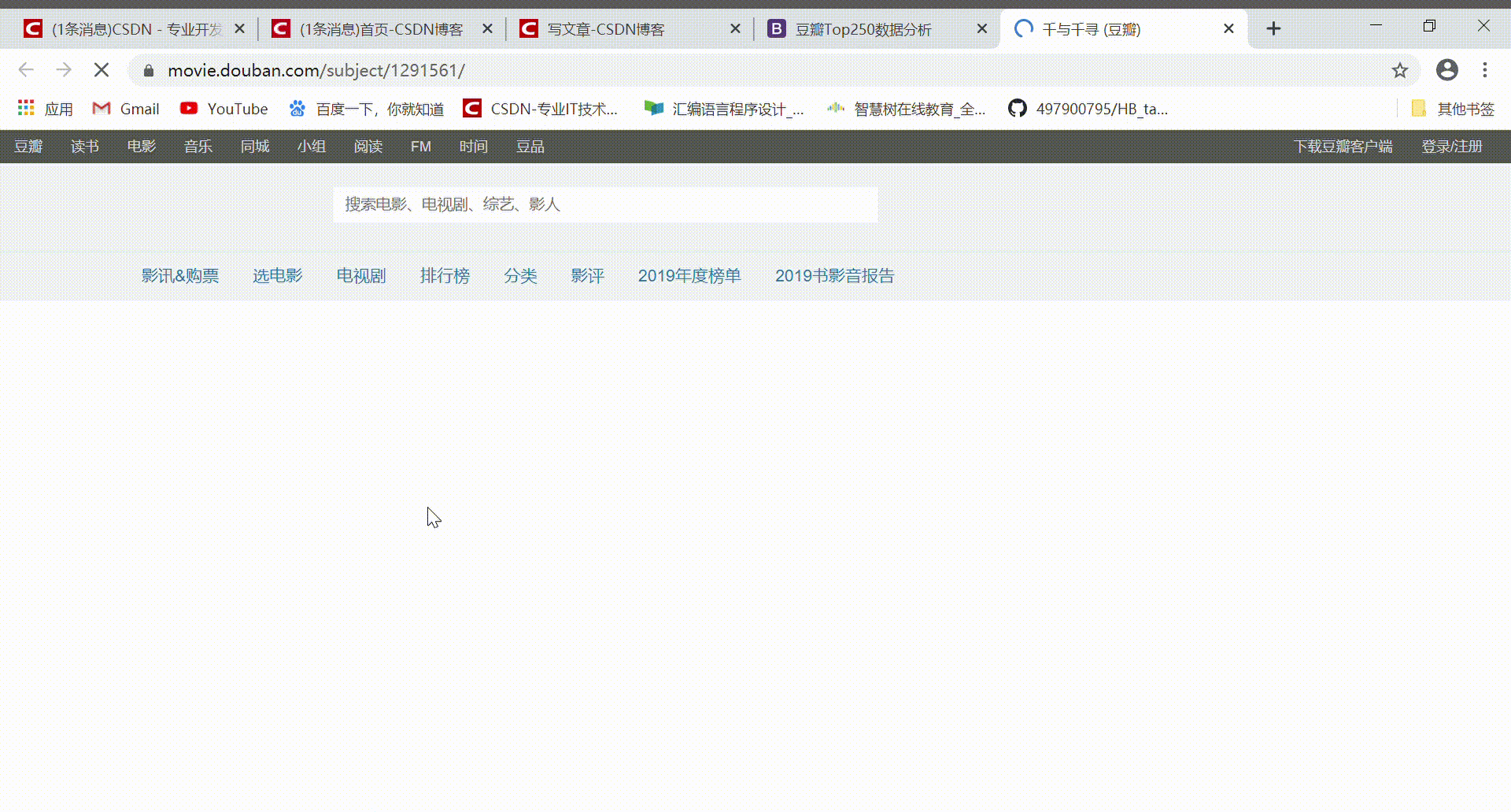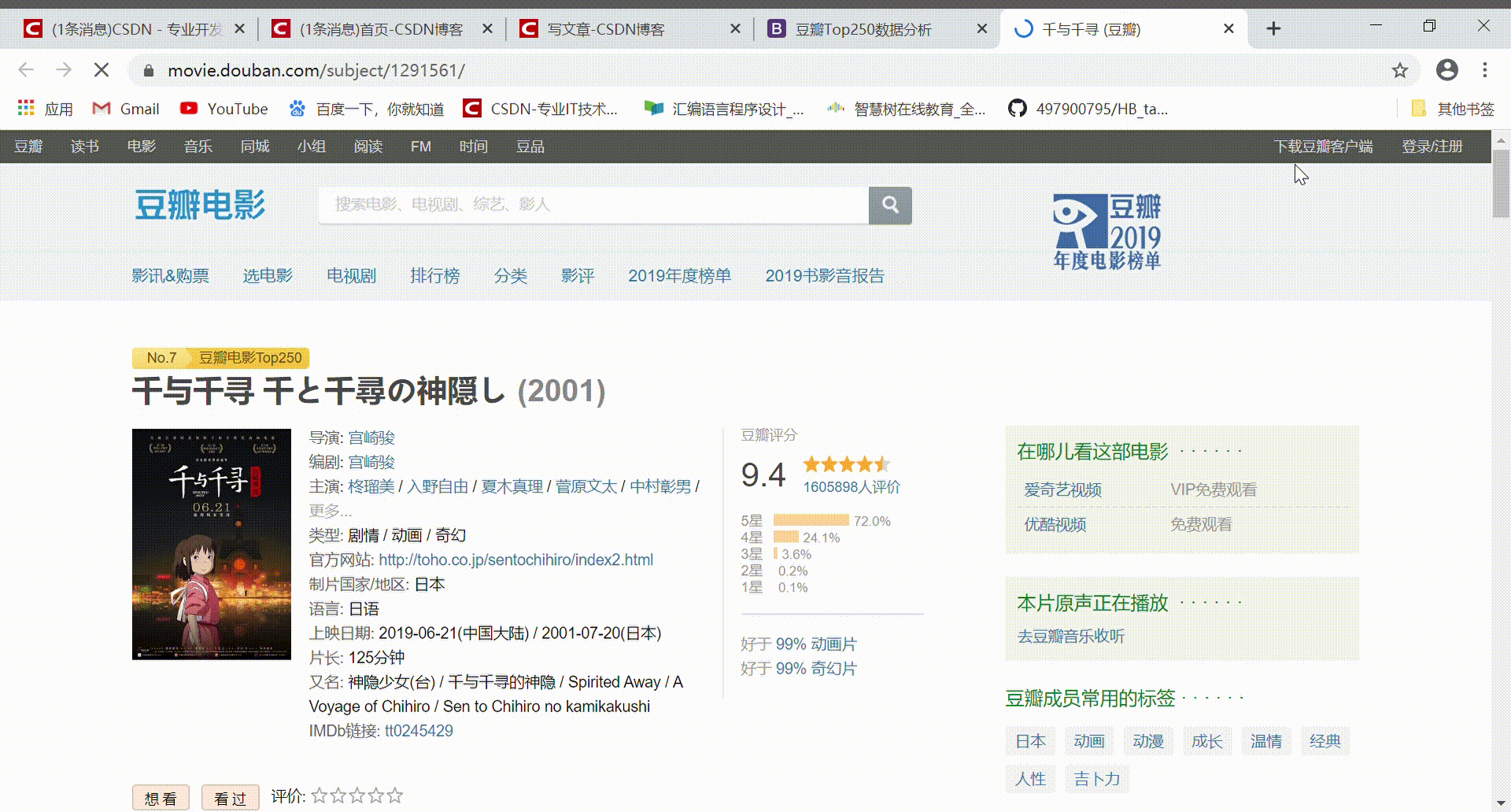
本论文基于Python编程语言实现了电影票房数据爬取与可视化系统。该系统主要分为两个部分,数据爬取和数据可视化。数据爬取部分采用 Python 的爬虫框架 Scrapy 和 BeautifulSoup,获取豆瓣电影网站的电影票房数据。数据可视化部分采用 Python 的数据可视化库 Matplotlib 和 Seaborn,将数据进行统计分析和可视化展示。
本论文详细介绍了系统的设计和实现过程。在数据爬取部分,采用 Scrapy 框架搭建了爬虫工程,通过 Xpath 和正则表达式解析网页,实现了数据爬取和存储。在数据可视化部分,采用 Matplotlib 和 Seaborn 绘制了电影票房数据的柱状图、折线图和散点图,实现了对数据的可视化展示和分析。
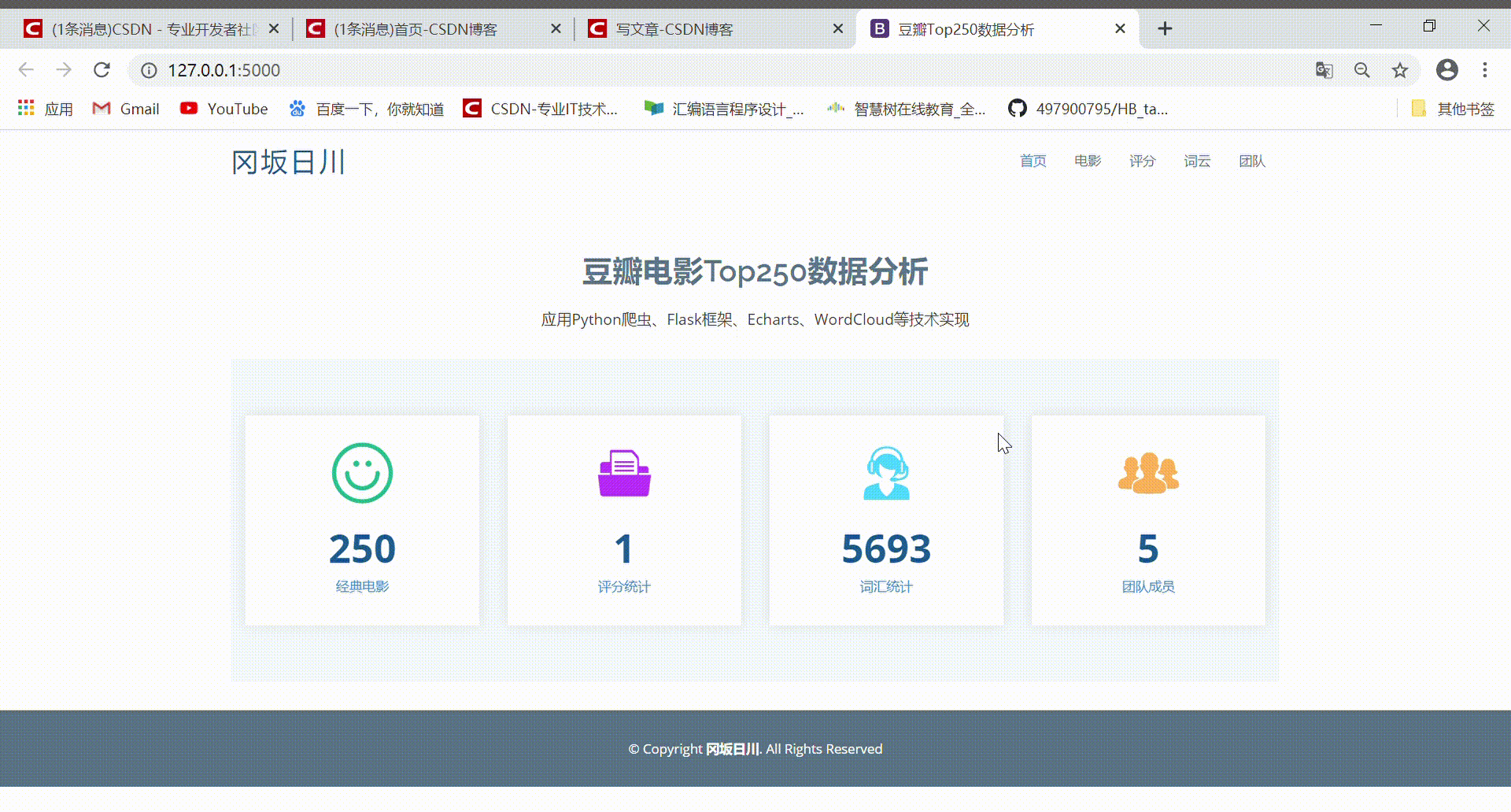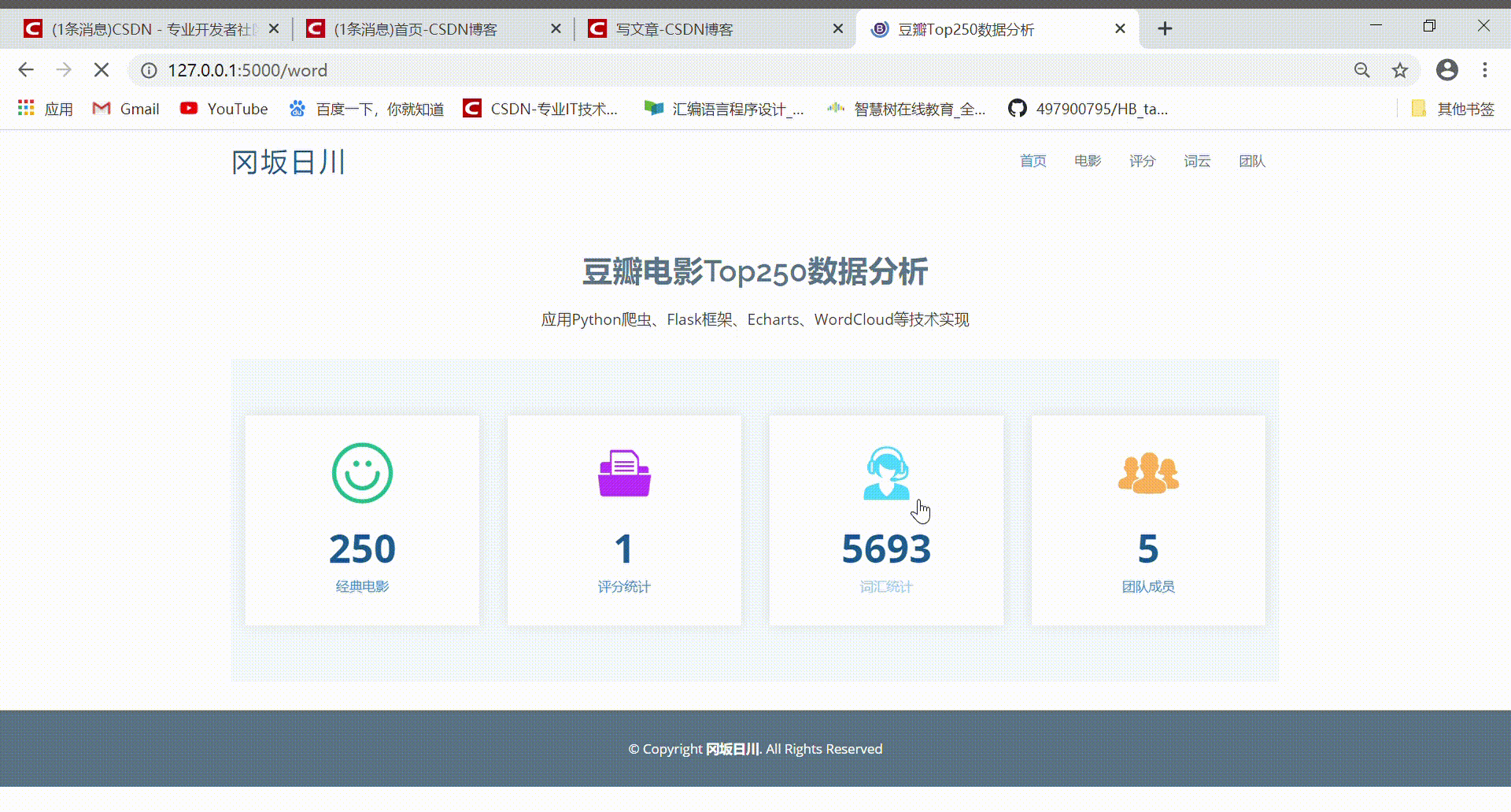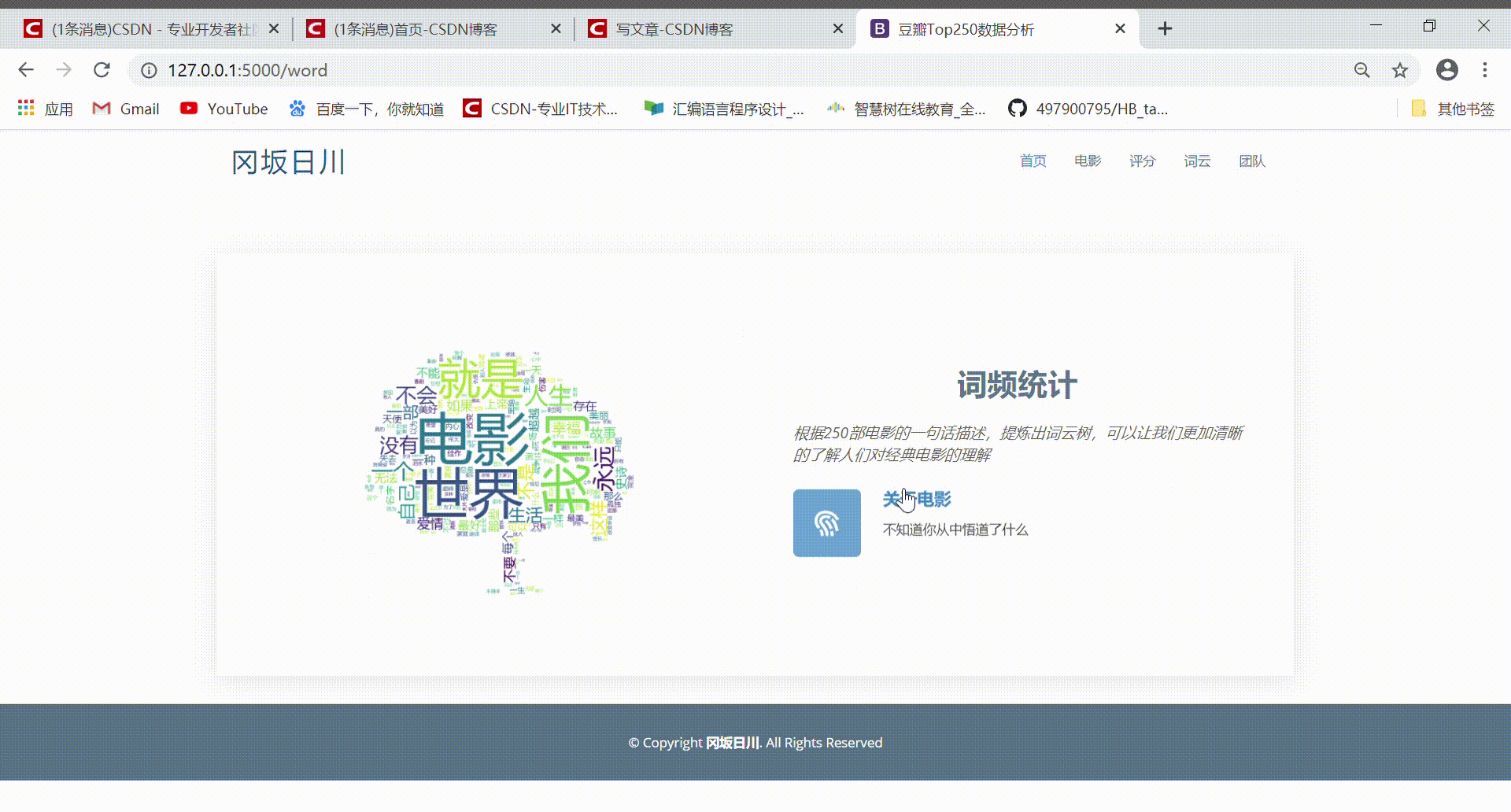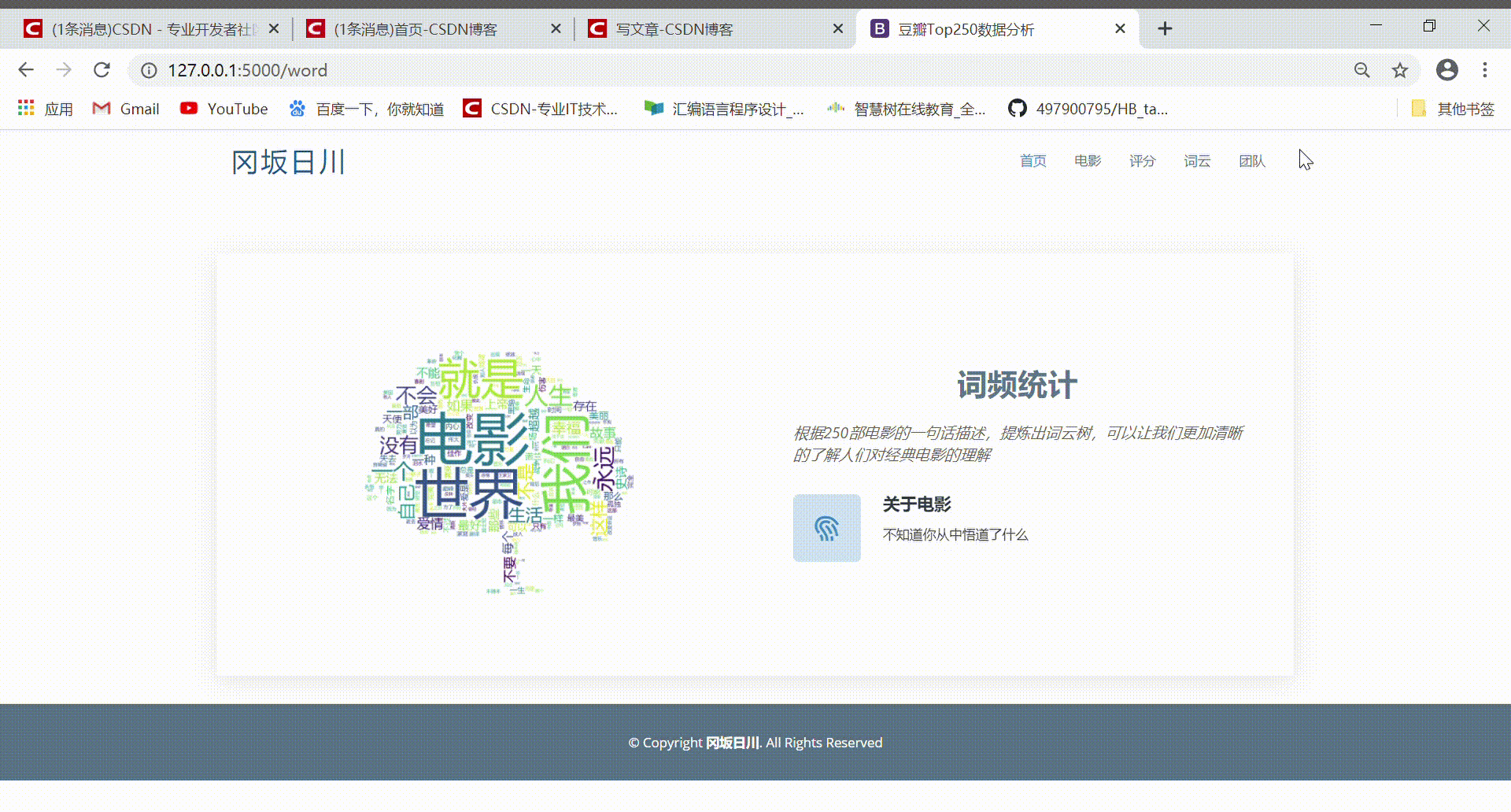
本系统实现了对电影票房数据的爬取和可视化,为电影从业者、电影爱好者和研究人员提供了一个方便快捷的数据获取和分析平台。同时,本系统也具有一定的实用性和推广价值。为了帮助用户进行影片选择,本文主要基于Python的Scrapy框架,设计并实现对豆瓣电影网上海量影视数据的采集,清洗,保存到本地。并用Pandas,Numpy库对影评进行处理,使用WordCloud对处理的影评进行词云展示,让用户对电影有一个认知。用Matplotlib、Pygal展示口碑+人气电影。
关键词:Python;电影数据;电影票房;数据分析;可视化
Abstract
This paper realizes the climbing and visualization system based on Python programming language. The system is mainly divided into two parts, data climbing and data visualization. The Python crawler framework Scrapy and BeautifulSoup are used to obtain the box office data of Maoyan film website. In the data visualization section, Python's data visualization libraries Matplotlib and Seaborn were used for statistical analysis and visualization display.
This paper details the design and implementation of the system. In the data crawl part, the Scrapy framework is used to build the crawler project, and the data crawl and storage are realized through Xpath and the data crawl by regular expression. In the data visualization section, Matplotlib and Seaborn were used to draw the bar chart, line chart and scatter plot of the movie box office data, realizing the visual display and analysis of the data.
This system realizes the climbing and visualization of film box office data, providing a convenient and quick platform for data acquisition and analysis for film practitioners, film lovers and researchers. At the same time, the system also has a certain practical and promotion value. In order to help users to choose films, this paper is mainly based on the Scrapy framework of Python, designing and realizing the collection, cleaning and saving to the local area. Use the Pandas and Numpy library to process the film reviews, and use the WordCloud to display the processed film reviews in the word cloud, so that users can have a cognition of the film. Use Matplotlib, Pygal to show word of mouth + popular movies.
Key words: Python; movie data; movie box office; data analysis; visualization
目 录