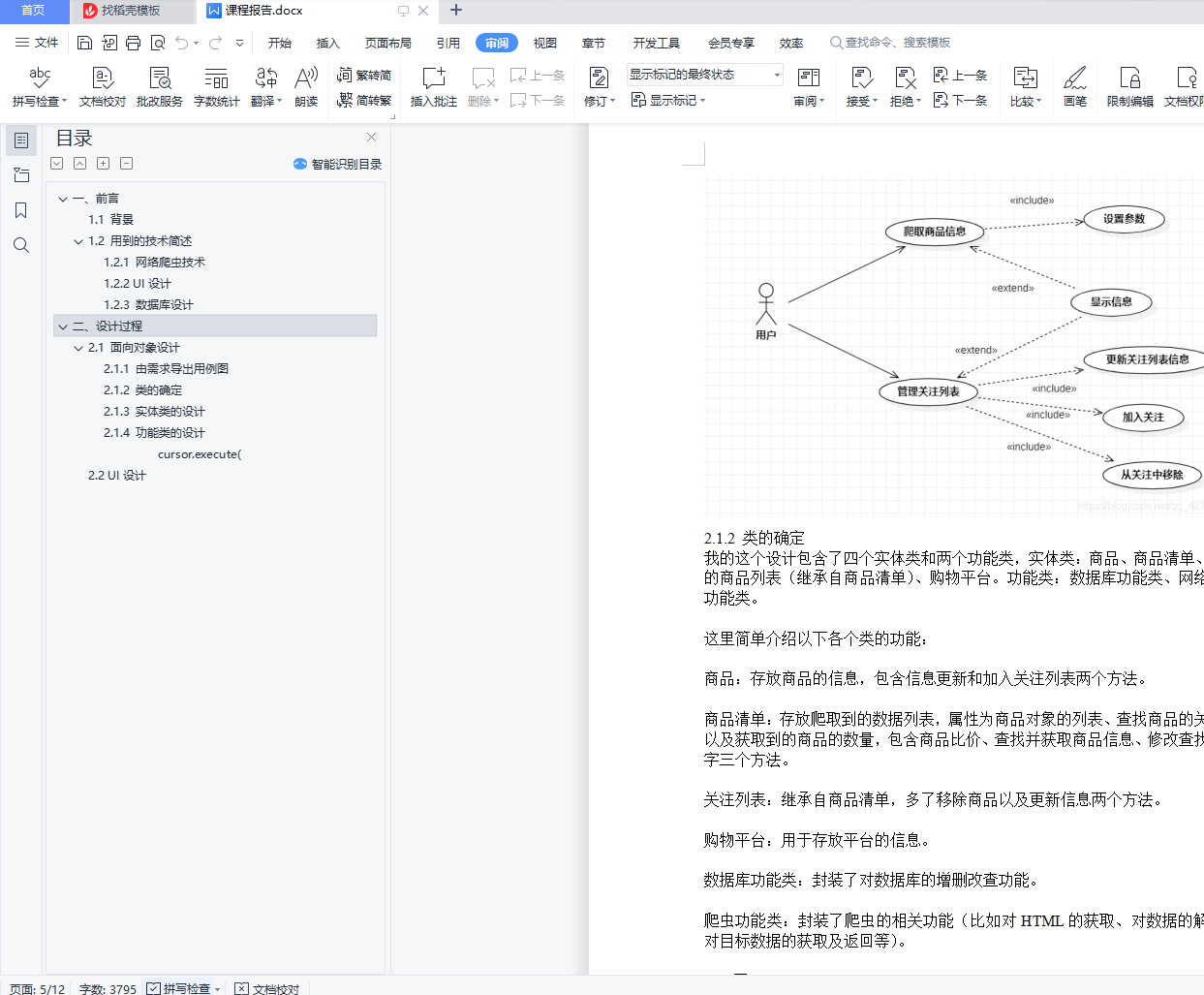
基于网络爬虫的商品询价系统的设计与实现 课程报告+Python项目源码

目录
一、前言
1.1 背景
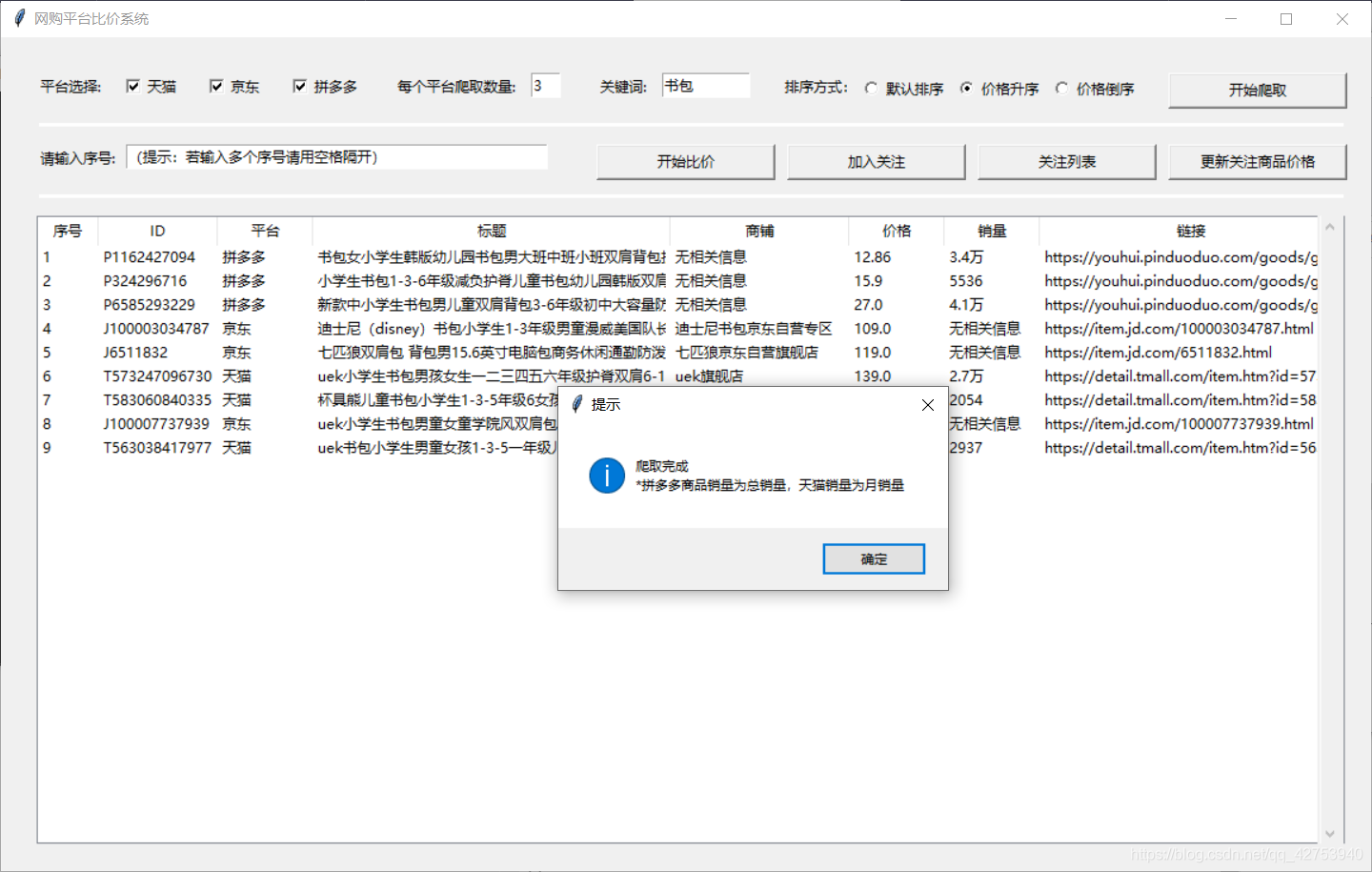
近几年来网络购物越来越流行,基本上每个人都有过网购经历,本着“货比三家”的原则,我们往往倾向于对商品进行大量的比较。然而不同的网购平台其商品也不尽相通,而跨网站的比较又着实比较麻烦,因此就有了做一个快捷的网购平台比价系统的想法,实现在一个界面内实现多网购平台商品的比价操作。
其实很早就萌生了做这个程序的念头,但是一直都觉得实现起来比较麻烦所以就鸽了,但是由于在做学校的Python课设时没有好的想法,就还是把这个给提了出来,真正实现之后发现也并不是很难。
1.2 用到的技术简述
既然是比价系统,就肯定要实现数据的获取,那么就难免需要网络爬虫技术、数据库技术以及简单的UI设计。
1.2.1 网络爬虫技术
我们用到的是requests+selenium的方法进行爬虫,其实简单的爬虫用不到selenium,requests就足够了,但是有些网站不是静态加载的,我们用requests就获取不到数据,因此这里也用一下selenium,以便于进行扩展。
requests:可以直接利用get方法获取目标页面的HTML文本,使用起来十分简单。
selenium:可以实现模拟操作,其操作可以做到与手动一样,从而获取页面的文本(手动操作即在页面上右键->查看源代码从而获取HTML文本),虽然可能会有点慢,但是可以很好的绕过网站的反爬虫程序。
既然已经获取到了HTML文本,那么就肯定需要进行解析,从而获取到我们想要的数据。常用的解析方法是BeautifulSoup和正则表达式re。
BeautifulSoup:利用HTML中的标签进行查找,在查找目标数据时需要观察目标数据在哪个Tag下,可以利用父Tag到子Tag的方式逐级查找,或者利用目标数据所在Tag的位置进行查找(这个方法风险比较大,网页源码稍有改动就有可能完蛋)。例如以下HTML(只是做个示例,没有详细学过HTML,可能会写错还请勿喷):
<tag1>
<title> a </title>
</tag1>
<tag2>
<title> b </title>
</tag2>
<tag3>
<title> c </title>
</tag3>
比如我们想要获取tag2下的title(即b),我们可以先查找tag1,然后查找title,然后获取title中的内容;也可以直接查所有的title,在返回的列表中选择第二个,之后获取其下的内容。