MATLAB实现的基于SVM和LDA-GA的基因图谱信息提取方法研究 毕业论文+源码


题 目 基于 SVM 和LDA-GA 的基因图谱信息提取方法的研究
摘 要:
本文针对提取基因图谱信息的问题,运用浮动顺序搜索算法、RBF 支持向量机和遗传线性判别算法(LDA-GA)等方法,在不处理噪声、降噪以及融入其他有价值的信息三种条件下分别建立能够有效提取样本基因图谱信息的模型,并利用样本数据针对每种条件下得到的基因“标签”的分类能力进行测试和分析。
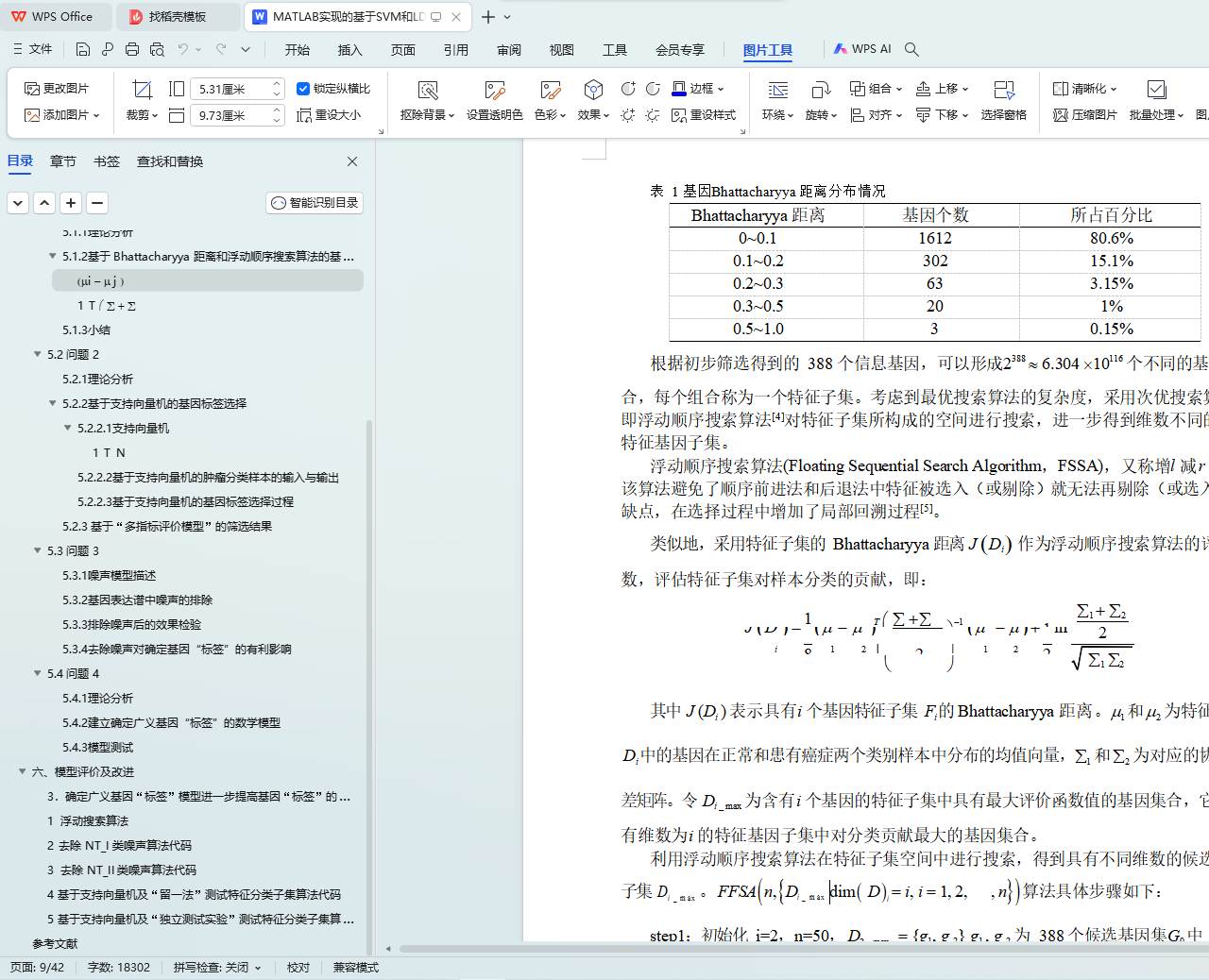
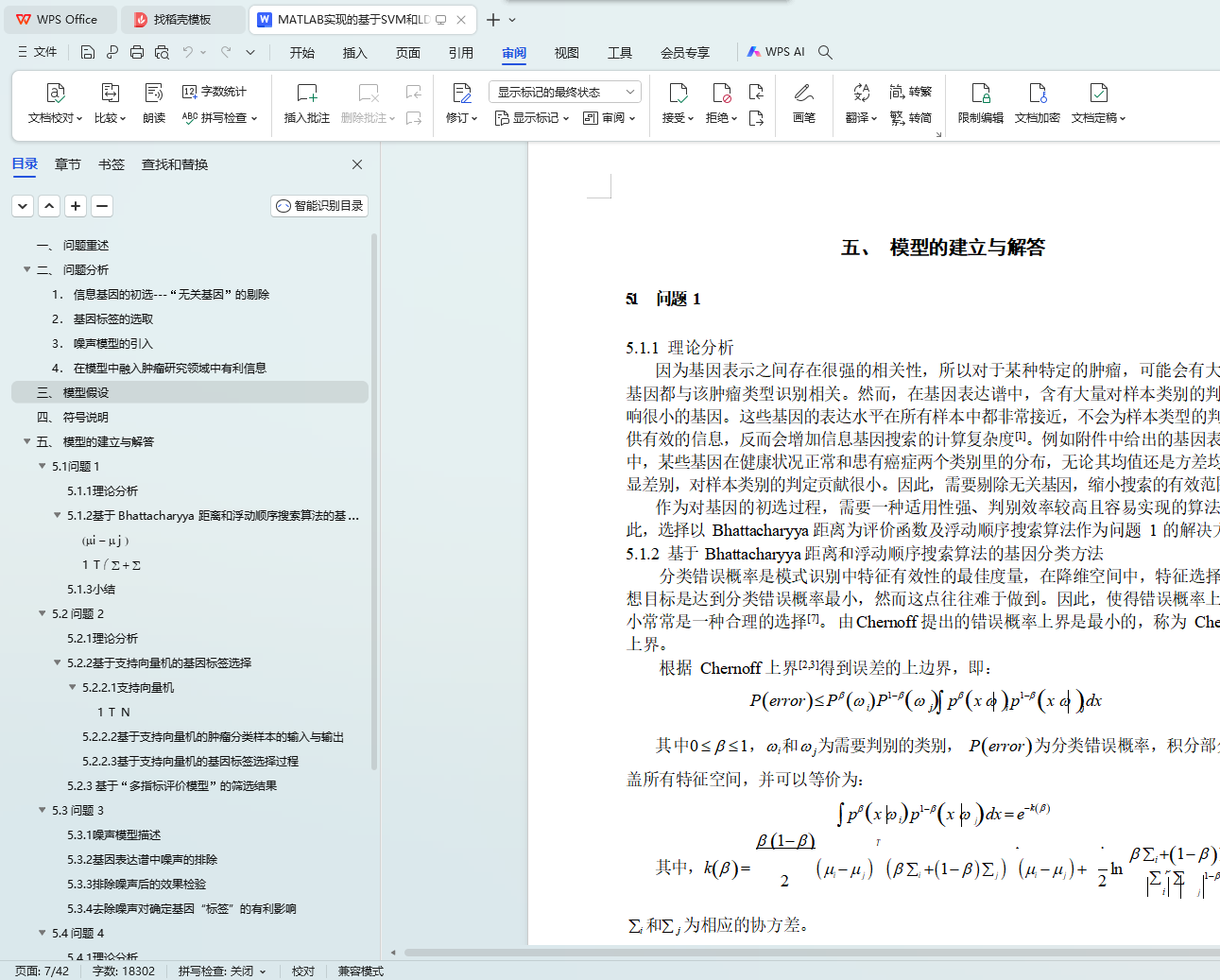
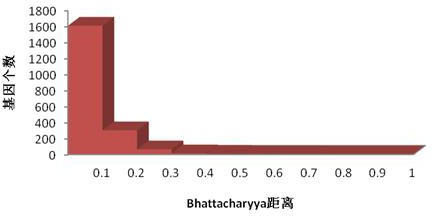
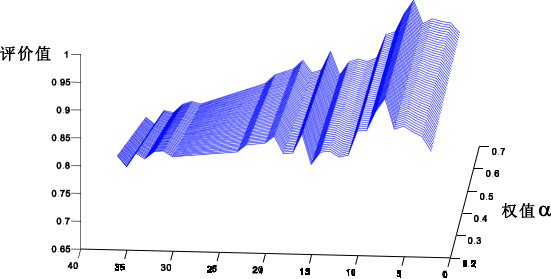
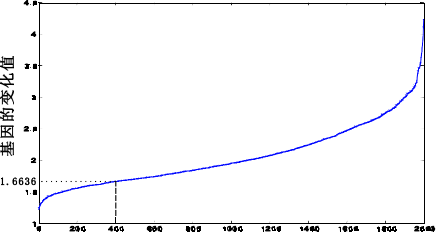
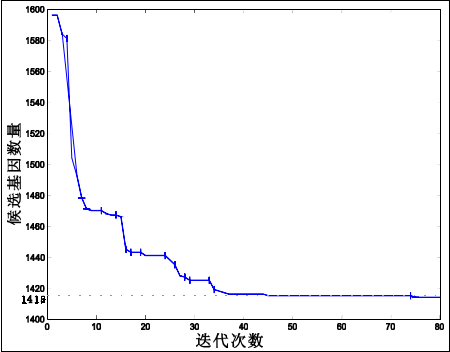
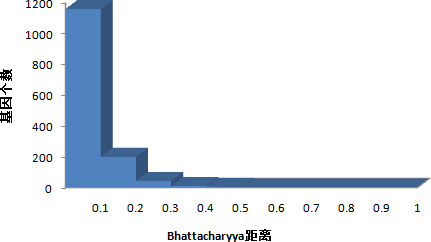
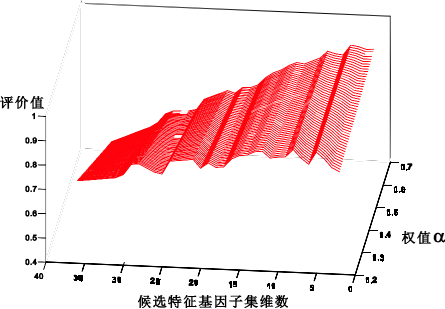
针对问题 1,首先以 Bhattacharyya 距离为评价函数,对样本中 2000 个基因进行无关基因的剔除,得到 388 个信息基因;然后,在信息基因集合中,根据浮动顺序搜索算法搜索得到 35 个候选分类特征子集,为问题 2 中基因标签的筛选提供必要条件。
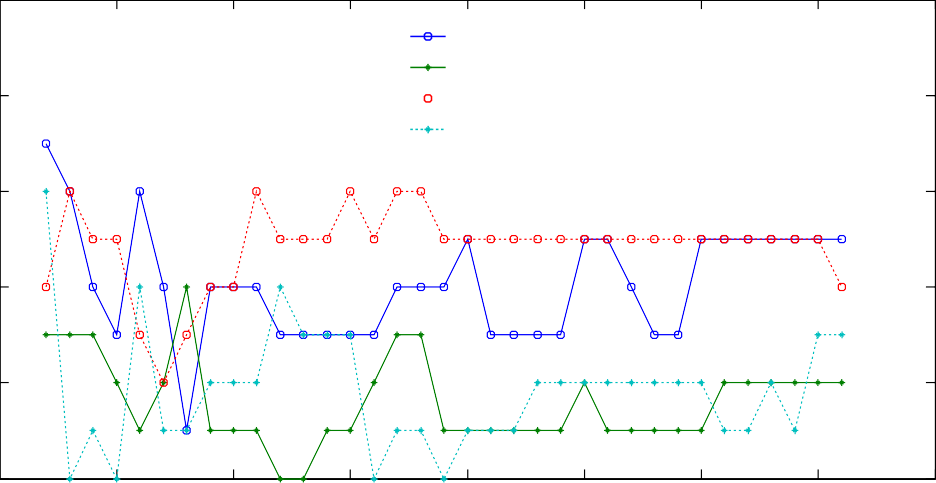
针对问题 2,根据样本数据,利用候选分类特征子集对 RBF 支持向量机进行训练, 采用“留一法”和“独立测试实验”对所建支持向量机进行测试。通过对测试结果的分析与评价,筛选出具有最佳分类效果的特征子集,作为基因“标签”。通过实验得到的基因“标签”为 7 维向量。
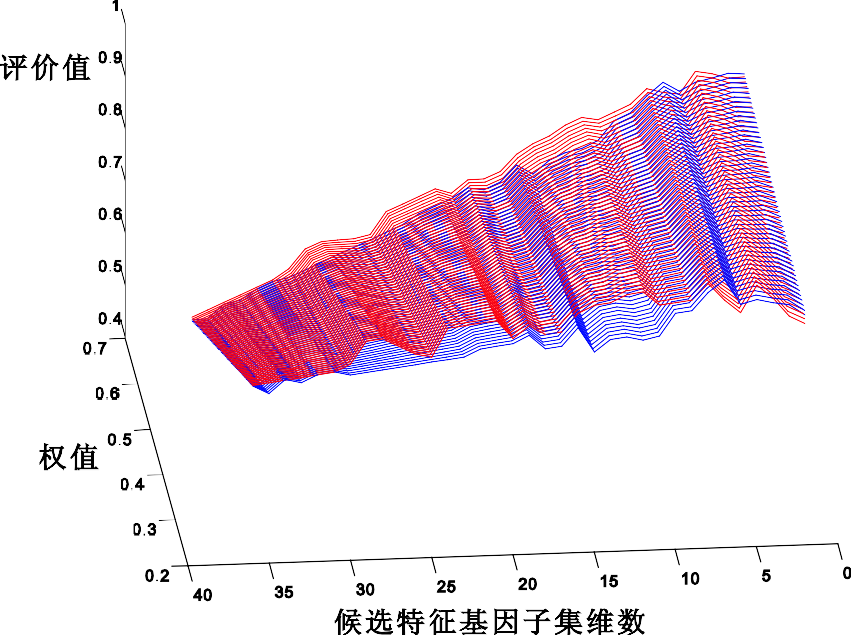
针对问题 3,分析 NT_I 及 NT_Ⅱ两类噪声,建立噪声模型并对样本数据进行降噪处理。运用处理后的样本数据,确定新的基因“标签”。实验结果表明,新的基因“标签” 具有更高的分类精度。
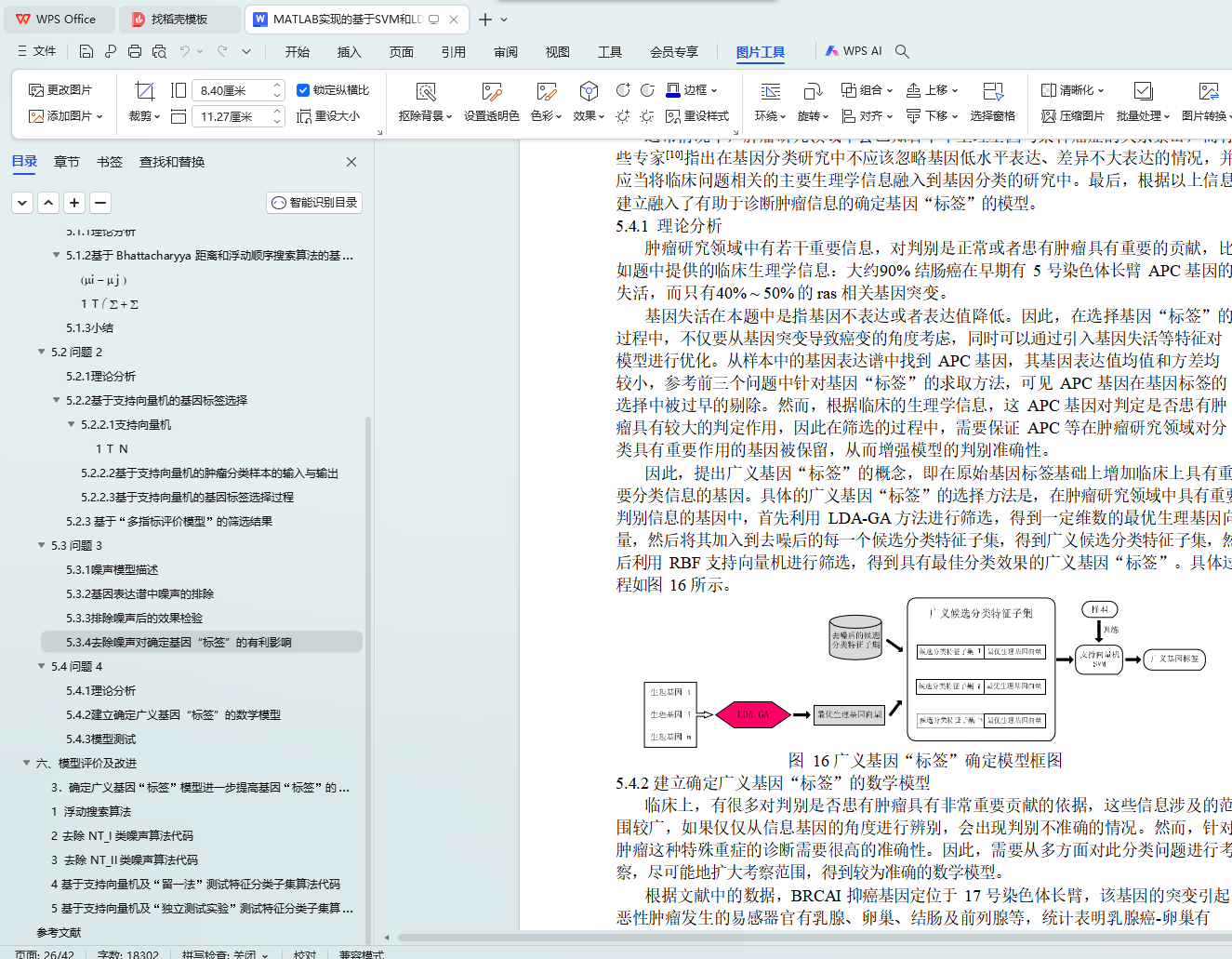
针对问题 4,根据有助于诊断肿瘤的相关信息,利用 LDA-GA 方法对有价值的生理基因进行筛选得到最优生理基因向量,与候选分类子集组合形成广义候选分类子集,并通过支持向量机对其筛选,确定广义基因“标签”。实验结果表明,广义基因“标签” 为 4 维向量,且具有更佳的分类效果。
关键词:Bhattacharyya 距离,浮动式顺序搜索算法,RBF 支持向量机,NT_I 及 NT_Ⅱ 噪声模型,LDA-GA 算法
目录
5.1.2 基于 Bhattacharyya 距离和浮动顺序搜索算法的基因分类方法
3.确定广义基因“标签”模型进一步提高基因“标签”的分类效果
5 基于支持向量机及“独立测试实验”测试特征分类子集算法代码